


主なポイント
- エージェントメモリとは、AIエージェントがすべてのやり取りを新規として扱うのではなく、時間を超えて情報を記憶する仕組みです。
- 通常、現在の文脈を保持する短期メモリと、事実や好み、教訓など持続的な情報を保存する長期メモリで構成されます。
- エージェントメモリは、ユーザーの好み、プロジェクトの慣例、過去のミス、ドメイン知識、前回の作業サマリーなどを保存できます。
- すべてを永久に保存することが目的ではなく、重要な情報のみを覚え、必要なときに取り出し、文脈ウィンドウの過負荷を防ぐことが重要です。Cloudflareの最近の発表では、エージェントが「重要なことを思い出す」ための機能として説明されています。
- 2026年4月時点で、メモリは主要な設計層となっており、Anthropic、OpenAIのAgents SDK、LangChain、新興のインフラ提供者による積極的な実装が進んでいます。
人工知能は推論やツールの活用において大きく進化していますが、多くのエージェントの大きな課題は、必要な情報を忘れやすいことです。通常のAIシステムは1つのセッション内では優れたパフォーマンスを発揮しますが、会話終了やタスクのリセット後には重要な文脈を失ってしまいます。この課題を解決するためにエージェントメモリが設計されています。AnthropicのManaged Agentsドキュメントでは、メモリストアを利用し、ユーザーの好みやプロジェクトの慣例、過去のミス、ドメイン文脈などをセッションをまたいでエージェントが保持できると説明されています。LangChainのメモリガイドも同様に、メモリによりAIエージェントは過去のやり取りを記憶し、フィードバックから学び、ユーザーの好みに適応できると述べています。
高い視点で言えば、エージェントメモリとは、AIエージェントが毎回ゼロから開始せず、時間を超えて有用な情報を保持できる仕組みのことです。このメモリには、会話履歴の短期記憶、ユーザーやプロジェクトに関する長期的な事実、前回の作業サマリー、過去の教訓、構造化された推論成果物などが含まれます。OpenAIのAgents SDKドキュメントではセッション履歴とより永続的なエージェントメモリが区別されており、AnthropicやLangChainもセッションを超えて維持される永続メモリを強調しています。
これは、次世代AIエージェントが単なる一回限りの応答ではなく、プロジェクトの運営、ワークフローの調整、継続的タスクの再訪、意思決定の個別化、時間をかけた改善など、より多くの役割を期待されているため重要です。メモリがなければ、そのビジョンはすぐに破綻します。
エージェントメモリとは具体的に何か?
「メモリ」という用語は曖昧に聞こえるかもしれませんが、AIにおいては複数の意味で使われています。エージェントの文脈では、単にコンテキストウィンドウを大きくするだけではなく、保存・取得・要約・呼び出しなどを組み合わせ、タスクやセッションを超えて有用な情報を保持する仕組みを指します。Anthropicのドキュメントでは、デフォルトでは各Managed Agentsのセッションが新規として開始し、セッション終了時に学習内容が失われるが、メモリストアによってセッションを超えて情報を保存できると説明しています。LangChainも概念的に、メモリを過去のやり取りを記憶し、エージェントが学び適応するためのシステムと定義しています。
この区別は重要です。なぜなら、単なる大きなコンテキストウィンドウと本当の意味でのメモリは異なるためです。コンテキストウィンドウは現在モデルに渡す情報を保持するだけですが、エージェントメモリは外部化され、永続的かつ選択的です。OpenAIのsandbox-agentドキュメントでは、メモリがセッション会話履歴とは別に存在し、過去の実行から得た教訓をサンドボックスワークスペース内のファイルに集約する形で説明しています。Cloudflareの発表でも、エージェントの会話から抽出された情報を必要な時に利用可能にする仕組みであり、全てをコンテキストに詰め込むものではないと述べられています。
なぜエージェントメモリが重要か
多くの実用的なタスクは一回限りのものではありません。AIエージェントがリサーチ、トレーディング、コーディング、運用、カスタマーサポートを支援する場合、継続性が必要です。たとえば、
- ユーザーの目標
- 過去の意思決定
- 前回のミス
- 好みのフォーマット
- プロジェクトの進行状況
- 再発見がコストとなる事実
などを覚えておく必要があります。Anthropicのメモリストアドキュメントでは、ユーザーの好み、プロジェクトの慣例、過去のミス、ドメイン文脈をセッションをまたいで保持する例が挙げられています。LangChainも、より複雑なタスクや繰り返しのユーザーインタラクションをこなす際にはメモリが重要になると述べています。
メモリがなければ、エージェントは同じ質問を繰り返し、指示を忘れ、プロジェクトの継続性を失い、文脈の再構築に無駄な時間を費やす傾向があります。
Cloudflareの最近の分析では、永続メモリにより、重要なことを思い出し、不必要な情報を忘れることでエージェントが時間とともに賢くなると説明されています。Anthropicの「dreaming」研究も、エージェントがセッション間で過去の行動を振り返りパターンを見つけ、将来のパフォーマンスを改善する方向性を示唆しています。
ユーザーにとってはより良い継続性、開発者にとってはプロンプト詰め込みの軽減とワークフロー設計の堅牢化、エージェントエコシステム全体にとっては単なる反応型から経験を蓄積するエージェントへの進化が期待できます。
エージェントメモリ (出典)
エージェントメモリとコンテキストウィンドウの違い
この区別は非常に重要です。
コンテキストウィンドウは現在モデルが受け取っているテキストやマルチモーダル入力のことです。一時的かつ制限があります。エージェントメモリは、ライブのコンテキスト外に保存され、必要なときに取り出されたり要約されたりする情報です。
Anthropicのcontext-engineering記事では、コンテキストは有限なリソースであり、慎重に管理する必要があると述べられています。Cloudflareの発表も、重要な情報をすべてのコンテキストウィンドウに詰め込むことなく利用可能にするという点を重視しています。
つまり、メモリは圧縮と選択性が重要となります。すべての細部を無限に記憶するのではなく、適切なタイミングで必要な情報を思い出すことが目的です。OpenAIの「memory and compaction」クックブックも、すべての証拠をライブプロンプトに保持するのではなく、圧縮と長期保存パターンを用いることで信頼性の高いエージェント設計を推奨しています。
エージェントメモリの主な種類
フレームワーク毎に多少異なる表現はありますが、大きく以下の分類にまとまりつつあります。
短期メモリ
短期メモリは、現在の会話やタスク、実行ループに関連する情報を指します。LangChainのガイドでは、メモリをリコールのスコープで部分的に扱い、Neo4jの開発者記事でも主要な3種類の一つと位置付けています。
短期メモリには、
- 最近の会話のやり取り
- 今回の実行でのツール出力
- 一時的な作業ノート
- 中間的な計画
などが含まれます。これは通常の「セッション状態」に近いですが、より高度なシステムではタスクの進行に応じて要約・圧縮されることもあります。OpenAIのAgents SDKドキュメントではセッションストアで会話履歴を保持するとされており、これは典型的な短期メモリです。
長期メモリ
長期メモリは、一般的に言う永続メモリのことです。Anthropicのメモリストアは、まさにこれを目的としています。好みや慣例、過去のミス、ドメイン文脈などをセッションを超えて保持します。Cloudflareも、重要な情報を時間をかけて覚える手段として永続メモリを位置付けています。
長期メモリには、
- ユーザーの好み
- プロジェクトの背景
- 過去の結論
- 再利用可能な知識
- 繰り返しの指示
- 長期的な事実
などが含まれ、繰り返し利用時のステートレス感を解消します。
推論メモリ
一部のシステムでは、エージェント自身の思考プロセスや教訓、ヒューリスティクスの記憶を第三のカテゴリーとして区別しています。Neo4jはこれを「推論メモリ」と呼び、短期・長期メモリとは異なるとしています。OpenAIのsandbox-agentドキュメントでも、単なる履歴ではなく、過去の実行から得た教訓を集約した形のメモリを説明しています。
推論メモリには、
- 過去に有効だった戦略
- 回避すべき落とし穴
- 分解パターン
- 自己改善メモ
などが含まれます。これは「好みを覚える」だけでなく、「次回より良く操作する方法を覚える」ことに繋がります。
エージェントメモリが保存できるもの
実際には、システム設計により様々な情報を保持できます。
Anthropicの例では、
- ユーザーの好み
- プロジェクトの慣例
- 過去のミス
- ドメイン文脈
が含まれます。
OpenAIのsandbox-agentドキュメントによれば、
- タスク固有の学び
- 要約された知識
- 再利用可能な作業知識
なども保存可能です。
Cloudflareは、重要なもの、忘れるべきもの、後で表示すべきものを選択的に記憶する概念を提唱しています。
LangChainは、過去のやり取りやフィードバックパターンも含めてエージェントが記憶できると述べています。
エージェントメモリの仕組み
共通した単一のアーキテクチャはありませんが、ほぼすべてのメモリシステムは以下のような流れを持ちます:
- やり取りや実行から有用な情報をキャプチャ
- それを永続的な構造に保存
- 新しいタスク開始時に関連部分を取得
- アクティブなエージェントループ内でそのメモリを参照または注入
- タスク終了や新たな学びが生じた際にメモリを更新
Anthropicのドキュメントでは、永続メモリをエージェントがセッションを超えて保持できる仕組みと説明しています。OpenAIのsandbox-agentドキュメントも、ワークスペース内のファイルとして保存し、将来の実行で学べるようになっていると記載しています。Cloudflareも会話から情報を抽出し後で利用できるようにしています。
このパターンにより、メモリはデータベース的要素、リトリーバル層、要約層の組み合わせとなります。システムによっては構造化ファイルやベクトル検索、階層的な記憶管理、即時取得と深層読み込みの組み合わせなど様々な方法が採用されています。Reddit上でのAnthropicのメモリアプローチに関する議論では、トップダウンのカテゴリ階層が示されましたが、これは公式ドキュメントではないため、参考情報として扱うべきです。
現代のメモリシステムは、単なるテキストの保管庫ではなく、構造化され、クエリ可能なものを目指しています。
現在のフレームワークにおけるエージェントメモリ
Anthropic
AnthropicのManaged Agentsドキュメントは、エージェントメモリについて最も明確な説明を提供しています。メモリストアにより、エージェントは情報をセッションを超えて保持でき、なければ毎回ゼロから始まるとされています。AI SDKとの統合ドキュメントでは、Claude向けの構造化メモリツールインターフェースも参照されています。
Anthropicの「dreaming」研究(2026年5月報告)は、セッション間で過去の行動を振り返り将来のパフォーマンスを向上する方法を探るもので、メモリを保存のみに留まらず、内省的な改善手段と捉えていることが示唆されます。
OpenAI
OpenAIのAgents SDKは、マルチステップ作業を完了するために必要な状態を保持できることを強調しています。SDKメモリでは、会話セッションメモリとより永続的なsandbox-agentメモリが区別されています。sandboxメモリは、ワークスペース内のファイルに過去の実行から学んだ内容を保存し、将来の実行で活用できる形で説明されています。メモリ圧縮や管理の重要性もクックブックで示されています。
LangChain
LangChainのガイドでは、過去のやり取りを記憶し、フィードバックから学び、ユーザーの好みに適応するためのシステムとしてメモリが説明されています。やり取りが増え、タスクが複雑になるほど重要度が増す概念的レイヤーと位置付けられています。
Cloudflare
Cloudflareの2026年4月発表では、メモリを管理されたサービスと位置付け、重要な情報をすべてのコンテキストウィンドウに詰め込むことなく記憶できる点を強調しています。これは、テキストの単純再生から選択的なメモリシステムへの業界全体のシフトを反映しています。
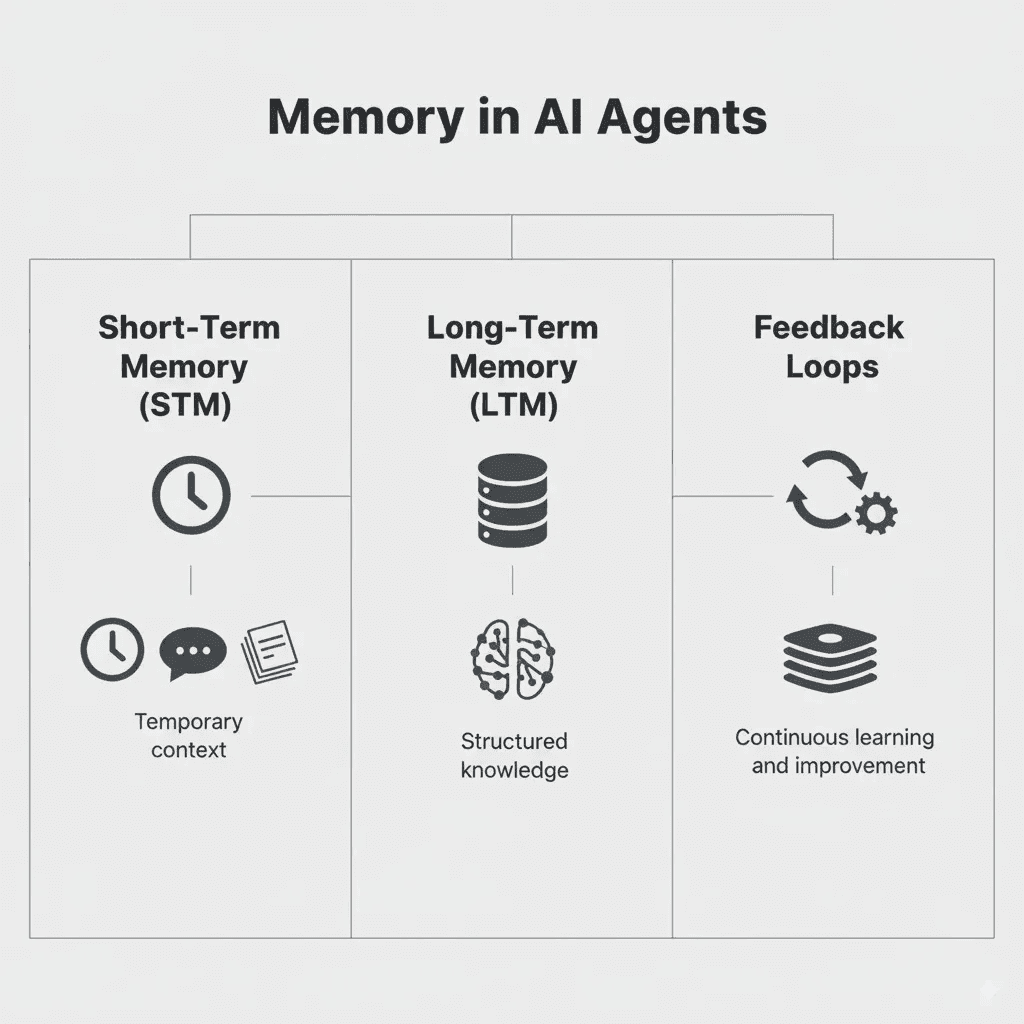
AIエージェントメモリの種類 (出典)
エージェントメモリが難しい理由
理論上はシンプルに思えますが、実装は困難です。
全てを記憶するべきではない ー 効率的なメモリシステムは、何を保持すべきか判断しなければなりません。全てを保存すればノイズやコストが増大し、保存が不十分だとエージェントが忘れやすくなります。Cloudflareの「重要なことだけ覚え、不必要なことは忘れる」という表現がこの課題を端的に示しています。
すべてのメモリを毎回利用するべきではない ー 有用な記憶も、適切なタイミングで提示されなければ意味がありません。Anthropicのcontext-engineering記事は、コンテキストの有限性と適切な情報選択の重要性を強調します。
メモリが陳腐化する可能性 ー ユーザーの好みやプロジェクトの方向性が変わると、古いメモリが障害になることもあります。Anthropicはチャットメモリの展開時に、ユーザーによる可視化・編集・無効化を重視しており、Claudeの消費者向けメモリアップグレードでも同様に表示・編集・削除・無効化が可能となっています。
メモリ設計は安全性に影響する ー 不適切なメモリ設計は誤った前提を強化したり、機密情報を漏洩したり、不要なものを保持する原因にもなります。消費者向けAIメモリに関する一般的な懸念として、プライバシーや予期しない心理的影響が挙げられますが、これらはエージェントシステム固有の問題ではありません。
エージェントメモリのメリット
課題は多いですが、エージェントメモリは品質向上に大きく寄与します。
継続性の向上 ー プロジェクトの慣例や過去のミスなど、具体例を挙げてAnthropicが説明しているように、エージェントの反復性やステートレス感を改善します。
パーソナライズの向上 ー 記憶された好みや文脈により、毎回基本から学び直すことなくユーザーに適応できます。LangChainも好みへの適応を明記しています。
効率性の向上 ー 既知の文脈があれば、背景の再構築や冗長な質問に費やすトークンや時間が削減されます。Cloudflareは、コンテキストウィンドウの過負荷防止が効率向上と直結することを強調しています。
信頼性の向上 ー OpenAIのメモリ圧縮やsandboxメモリのパターンは、過去の教訓を保持することで繰り返し同じミスをしない信頼性向上に貢献します。
長期的な有用性 ー プロンプト単位でなくプロジェクトを記憶できるエージェントは、リサーチやコーディング、分析、運用など継続的なワークフローでより価値を発揮します。Anthropic、LangChain、OpenAIがいずれも永続メモリが複数セッション対応に必須とするのは、このためです。
エージェントメモリとRAG(検索拡張生成)の違い
この違いも押さえておくべきポイントです。
RAGは通常、プロンプトに関連する外部ドキュメントや知識ソースを検索・取得することを指します。一方、エージェントメモリは、過去のやり取りや実行からエージェント自身が学び、保存・要約した情報を取得することです。
両者は重なる場合もありますが、同一ではありません。たとえば、エージェントがドキュメントライブラリへRAGを使う一方で、ユーザーの好みや過去のミスをメモリに残しておく場合もあります。OpenAIやAnthropicのドキュメントでは、メモリをエージェント継続性のための永続層とし、単なるドキュメント参照とは差別化されています。
Web3・暗号資産領域におけるエージェントメモリの重要性
AIエージェントがオンチェーントレーダーやウォレット運用、リサーチアシスタント、ガバナンス参加者、A2Aコマースの担い手などになる場合、メモリが必須です。トレーディングエージェントは戦略設定や過去のミス、リスクルールを記憶し、AIウォレットはユーザー権限や定期的な支出制限などを覚えておく必要があります。自律的なオンチェーンリサーチエージェントは、時間をかけてテーマを追跡するためのプロジェクト記憶が必要です。
つまり、エージェントメモリは抽象的なAI概念だけでなく、
- AIエージェントウォレット
- 自律的なオンチェーントレーディング
- DeFi
- エージェント間コマース
の基盤でもあります。
まとめ
エージェントメモリは、AIシステムが毎回リセットされずに継続性を維持できるためのレイヤーです。
短期的な作業文脈、長期的な知識、将来的な行動指針としての推論メモリなどが含まれます。Anthropic、OpenAI、LangChainなど多くのインフラプロバイダーが、メモリを設計の主要要素と位置付けています。
AIエージェントがシンプルなチャットから持続的なデジタルワーカーへと進化する中、エージェントメモリは最も重要な概念の一つとなっています。AIエージェントや自律ワークフロー、チェーン抽象化、RWAs、PayFiなどの最新動向を先取りしたい方は、Phemexが安全かつ使いやすいプラットフォームで市場を探索し、新しい機会の発見や取引戦略の強化をサポートします。