


Points clés
- La mémoire d’agent désigne les mécanismes permettant aux agents IA de conserver des informations entre plusieurs interactions, au lieu de repartir de zéro à chaque échange.
- Elle comprend généralement une mémoire à court terme (contexte actuel) et une mémoire à long terme (faits, préférences, leçons persistantes).
- Elle peut stocker, entre autres, les préférences utilisateurs, les conventions de projet, les erreurs passées, les connaissances métier et des résumés d’actions précédentes.
- L’objectif n’est pas de tout enregistrer, mais de retenir ce qui compte, de le retrouver au bon moment, et de ne pas surcharger le contexte actif de l’IA. L’annonce récente de Cloudflare sur l’Agent Memory met en avant cette capacité à "se souvenir de l’essentiel" sans saturer le contexte.
- En avril 2026, la mémoire devient un élément central dans l’architecture des agents IA, avec des solutions concrètes d’Anthropic, du SDK OpenAI Agents, de LangChain, etc.
L’intelligence artificielle progresse dans le raisonnement et l’utilisation d’outils, mais l’un de ses défis persistants reste étonnamment simple : la capacité à ne pas oublier. Un agent IA standard excelle dans une session, puis perd les informations clés dès que la conversation se termine ou que la tâche est réinitialisée. C’est ce que la mémoire d’agent vise à résoudre. Les documents d’Anthropic sur les agents gérés décrivent la mémoire comme un moyen de transporter les préférences utilisateur, conventions, erreurs passées ou contexte métier d’une session à l’autre. Le guide de LangChain confirme que la mémoire permet à l’IA de retenir les interactions précédentes, d’apprendre des retours et de s’adapter aux préférences.
Au sens large, la mémoire d’agent regroupe les systèmes et mécanismes permettant à un agent IA de conserver des données utiles dans le temps, plutôt que de recommencer à zéro. Cette mémoire peut inclure l’historique des conversations, des faits sur un utilisateur ou un projet, des résumés de travaux, des apprentissages issus d’expériences antérieures, voire des traces structurées de raisonnement. Le SDK OpenAI Agents distingue l’historique d’une session de la mémoire d’agent à plus long terme, et Anthropic ainsi que LangChain mettent l’accent sur la persistance des données mémorisées d’une session à l’autre.
C’est essentiel, car les nouveaux agents IA ne se limitent plus à répondre à une question isolée. Ils doivent gérer des projets, organiser des workflows, suivre des tâches en cours, personnaliser des décisions et s’améliorer à chaque interaction. Sans mémoire, ces fonctions sont inaccessibles.
Qu’entend-on exactement par mémoire d’agent ?
Le terme peut sembler vague, car la "mémoire" en IA revêt plusieurs sens. Chez les agents, il ne s’agit pas simplement d’une fenêtre de contexte élargie. On parle d’un ensemble de stockage, de récupération, de synthèse et de rappel qui aide l’agent à préserver l’essentiel au fil des tâches ou sessions. Selon Anthropic, chaque session d’agent démarre à neuf et oublie ce qui a été appris à la fermeture, ce que la mémoire vient corriger. LangChain exprime l’idée dans des termes similaires, la mémoire étant ce qui permet à l’agent de retenir et d’apprendre.
Cela fait la différence, car une fenêtre de contexte étendue n’est pas une vraie mémoire : elle ne contient que ce qu’on lui passe à l’instant t. La mémoire d’agent est externe, persistante et sélective. Selon OpenAI, la mémoire distille les leçons extraites des sessions précédentes et les stocke dans des fichiers accessibles à l’agent. Cloudflare décrit aussi son système comme un dispositif d’extraction et de mise à disposition ciblée des informations, au lieu de tout injecter dans le contexte.
Pourquoi la mémoire d’agent est-elle cruciale ?
La plupart des tâches utiles nécessitent une continuité.
Si un agent IA assiste dans la recherche, le trading, le codage, les opérations ou le support client, il lui faut souvent :
- retenir les objectifs,
- rappeler des décisions passées,
- se souvenir d’erreurs précédentes,
- respecter des formats préférés,
- conserver l’état d’un projet en cours,
- rappeler des faits coûteux à retrouver.
Anthropic cite explicitement les préférences, conventions, erreurs et contexte métier comme exemples de données à conserver d’une session à l’autre. LangChain note que la mémoire devient essentielle lorsque les agents traitent des tâches complexes et des échanges répétés.
Sans mémoire, les agents :
- répètent les mêmes questions,
- oublient les consignes,
- perdent la cohérence des projets,
- et gaspillent du temps à reconstruire le contexte.
Cloudflare explique que la mémoire persistante permet à l’IA de s’améliorer en retenant l’essentiel et en oubliant le superflu. Les travaux d’Anthropic sur le "rêve" des agents, relayés par Business Insider, explorent aussi la manière dont les IA peuvent analyser leur passé pour progresser.
Pour l’utilisateur, cela se traduit par une meilleure continuité. Pour les développeurs, par moins de "prompt stuffing" et de workflows fragiles. Et pour l’ensemble de l’écosystème, c’est ce qui distingue un agent réactif d’un agent réellement évolutif.
Mémoire d’agent IA (source)
Mémoire d’agent vs fenêtre de contexte
C’est la distinction fondamentale : la fenêtre de contexte est l’entrée active que le modèle voit actuellement, elle est temporaire et limitée. La mémoire d’agent stocke les informations en dehors du contexte actif et les restitue au besoin.
L’article d’Anthropic sur l’ingénierie du contexte insiste sur la nécessité de gérer soigneusement cette ressource. Cloudflare fait le même constat : la mémoire doit rendre l’information disponible sans saturer la fenêtre de contexte.
La mémoire s’apparente donc à une compression et une sélection : l’objet n’est pas la rétention infinie mais le bon rappel au bon moment. Le "cookbook" d’OpenAI sur la mémoire et la compaction montre comment recourir à des schémas de stockage efficaces améliore la fiabilité des agents.
Les principaux types de mémoire d’agent
Les frameworks emploient des termes variés, mais les catégories convergent :
Mémoire à court terme
Elle concerne l’information utile pour la conversation ou la tâche actuelle, ou la boucle d’exécution en cours. LangChain définit la mémoire en partie par son périmètre de rappel, et Neo4j distingue cette mémoire comme l’un des trois types majeurs.
Exemples :
- derniers échanges,
- résultats d’outils,
- notes temporaires,
- plans intermédiaires.
C’est ce qui s’apparente à l’"état de session" classique. Chez OpenAI, les "session stores" conservent l’historique d’une session : c’est la mémoire à court terme typique.
Mémoire à long terme
C’est la mémoire persistante par excellence. Celle qu’Anthropic conçoit précisément pour faire transiter préférences, conventions, erreurs et contexte d’une session à l’autre. Cloudflare positionne aussi la mémoire persistante comme le moyen de retenir ce qui importe dans le temps.
Exemples :
- préférences utilisateur,
- historique projet,
- conclusions passées,
- savoir réutilisable,
- instructions récurrentes,
- faits durables.
C’est ce qui évite à l’agent d’être "sans état" à chaque usage.
Mémoire de raisonnement
Certains systèmes identifient un troisième type : la mémoire du raisonnement, c’est-à-dire la trace du cheminement et des heuristiques de l’agent. Neo4j l’appelle "reasoning memory". OpenAI s’en rapproche en décrivant une mémoire des leçons extraites des expériences plutôt qu’un simple historique.
Cela peut inclure :
- stratégies efficaces précédemment,
- pièges à éviter,
- schémas de décomposition,
- notes d’auto-amélioration.
Ce point ouvre la voie à la mémoire du "comment mieux fonctionner à l’avenir".
Que peut stocker la mémoire d’agent ?
Selon le design, la mémoire d’agent peut contenir de nombreux types d’informations.
Anthropic fournit des exemples :
- préférences utilisateur,
- conventions de projet,
- erreurs passées,
- contexte métier.
Chez OpenAI, la mémoire est une synthèse des leçons, ce qui inclut :
- apprentissages spécifiques aux tâches,
- résumés compressés,
- savoir réutilisable.
Cloudflare conçoit la mémoire comme un rappel sélectif, suggérant que le système stocke :
- ce qui importe,
- ce qui doit être oublié,
- ce qui doit remonter plus tard.
LangChain ajoute :
- interactions antérieures,
- préférences,
- schémas de retours utilisateurs.
Fonctionnement de la mémoire d’agent
Chaque système a sa propre architecture, mais le schéma général est :
- Capturer les informations utiles.
- Stocker de manière persistante.
- Rappeler ce qui est pertinent au bon moment.
- Injecter ou référencer cette mémoire dans l’agent.
- Mettre à jour selon les nouvelles leçons ou à la fin de la tâche.
Chez Anthropic, la mémoire persistante voyage d’une session à l’autre. OpenAI stocke les leçons dans des fichiers accessibles pour les runs futurs. Cloudflare extrait et met à disposition l’information à bon escient.
La mémoire combine souvent base de données, couche de récupération, et synthèse. Certains systèmes s’appuient sur des fichiers structurés, d’autres sur des embeddings et la recherche vectorielle, d’autres sur une organisation hiérarchique. Certains combinent récupération rapide et lecture approfondie. Reddit évoque une hiérarchie top-down, mais par prudence on s’en tient aux sources officielles.
Ce qu’il faut retenir : les systèmes modernes visent une mémoire structurée et interrogeable, pas un simple archivage.
La mémoire d’agent dans les frameworks actuels
Anthropic
Anthropic décrit clairement la mémoire d’agent dans ses documentations. Elle permet à l’agent de porter l’information d’une session à l’autre, et sans elle, chaque session démarre à zéro. L’intégration SDK d’Anthropic mentionne aussi un outil mémoire structuré pour Claude.
Le "rêve" d’Anthropic, annoncé en mai 2026, explore même comment un agent peut analyser son comportement passé pour s’améliorer dans le futur : donc la mémoire n’est plus un simple stockage, mais une voie vers l’auto-amélioration.
OpenAI
Le SDK OpenAI Agents précise que les agents conservent assez d’état pour mener des tâches complexes. La mémoire du SDK distingue la session de la mémoire persistante (sandbox). Cette dernière permet à un agent d’apprendre des expériences précédentes à travers des fichiers spécifiques. Le "cookbook" OpenAI traite également de la compaction et du contrôle de la mémoire pour assurer la fiabilité.
LangChain
Le guide de LangChain présente la mémoire comme le système qui retient les échanges antérieurs, permettant à l’agent de s’adapter et d’apprendre des retours. Cette couche devient critique avec la complexité croissante des tâches.
Cloudflare
L’annonce d’avril 2026 de Cloudflare présente la mémoire comme un service géré, dont le but est d’aider les agents à retenir ce qui compte sans saturer le contexte, confirmant l’évolution vers une mémoire sélective.
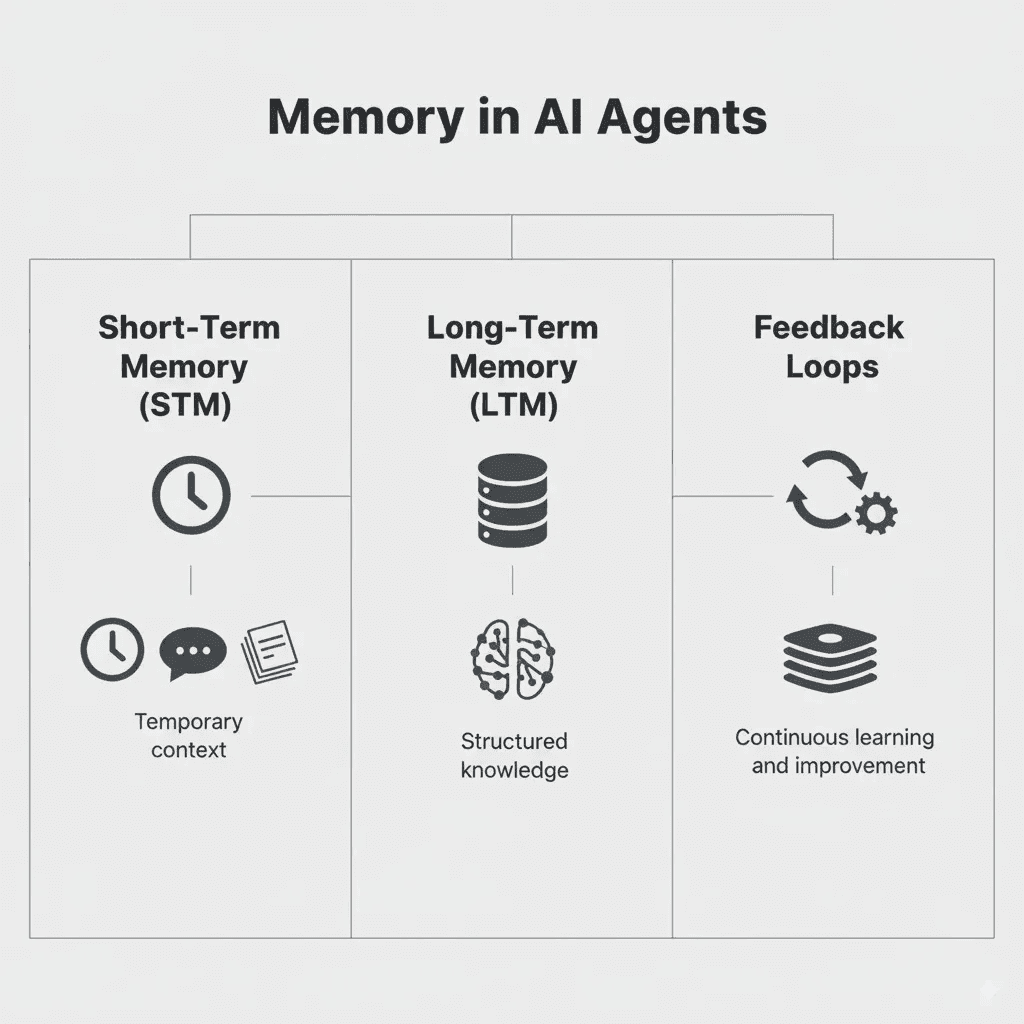
Types de mémoire d’agent IA (source)
Pourquoi la mémoire d’agent est-elle complexe ?
En théorie simple, en pratique difficile.
Tout ne doit pas être conservé : Un bon système doit sélectionner ce qui mérite d’être gardé. Stocker tout rend la recherche inutilement complexe, stocker trop peu laisse l’agent "amnésique". Cloudflare résume ce dilemme par "retenir l’essentiel, oublier le reste".
Toute mémoire ne doit pas être rappelée à chaque fois : Même une bonne mémoire n’est utile que si le rappel est contextuel. Anthropic insiste sur la gestion fine du contexte : rappeler trop de données nuit autant que pas assez.
La mémoire peut devenir obsolète ou erronée : Si les préférences ou la direction d’un projet changent, la mémoire peut devenir inappropriée. Anthropic met en avant la visibilité, l’édition et la désactivation de la mémoire pour garder le contrôle utilisateur. Les évolutions de la mémoire chez Claude intègrent la possibilité de voir, modifier ou supprimer la mémoire.
Le design de la mémoire impacte la sécurité : Une mémoire mal conçue peut renforcer de fausses hypothèses, exposer des informations sensibles ou conserver des éléments à supprimer. Certains débats publics s’inquiètent aussi de la vie privée, même si ces sujets dépassent le cadre des agents.
Avantages de la mémoire d’agent
Malgré les défis :
Meilleure continuité : L’agent devient moins répétitif. Anthropic donne l’exemple concret des conventions de projet et erreurs passées.
Meilleure personnalisation : Les préférences et contextes mémorisés permettent à l’agent de s’adapter progressivement à l’utilisateur. LangChain met en avant cette adaptation.
Meilleure efficacité : Un agent informé du contexte évite de redemander inutilement et gagne du temps, en phase avec la logique de Cloudflare.
Meilleure fiabilité : Les schémas de mémoire et de compaction d’OpenAI montrent que la mémoire améliore la fiabilité en évitant la répétition d’erreurs.
Utilité accrue à long terme : Un agent qui retient un projet dans la durée devient précieux pour la recherche, le développement, l’analyse ou l’opérationnel — comme le soulignent Anthropic, LangChain et OpenAI.
Mémoire d’agent vs RAG (Retrieval-Augmented Generation)
Il est important de distinguer :
Le RAG consiste à interroger des documents ou bases externes. La mémoire d’agent stocke ce que l’agent a appris ou synthétisé lors d’interactions précédentes. Les deux s’articulent mais ne se confondent pas : un agent peut combiner RAG pour interroger une base documentaire et mémoire pour retenir préférences et erreurs. OpenAI et Anthropic traitent la mémoire comme une couche de continuité spécifique, distincte de la simple recherche documentaire.
Pourquoi la mémoire d’agent est importante pour la crypto et le Web3
Des agents IA amenés à devenir traders onchain, gestionnaires de portefeuille, assistants de recherche, acteurs de la gouvernance ou de la "A2A commerce" ont besoin de mémoire. Un agent de trading doit retenir ses réglages de stratégie, erreurs passées, règles de risque. Un wallet IA doit stocker les permissions utilisateur ou des limites récurrentes. Un agent de recherche autonome doit suivre une logique de projet sur la durée.
La mémoire d’agent n’est donc pas qu’un concept IA abstrait. C’est la base pour :
- wallets d’agents IA,
- trading autonome onchain,
- DeFi,
- commerce agent-à-agent.
Conclusion
La mémoire d’agent permet à l’IA de conserver la continuité au lieu de repartir de zéro à chaque fois.
Elle couvre le contexte de travail immédiat, le savoir durable, et de plus en plus la mémoire du raisonnement pour améliorer l’agent dans le temps. Anthropic, OpenAI, LangChain et d’autres considèrent désormais la mémoire comme un pilier de la conception des agents IA.
Alors que les agents IA évoluent vers des assistants numériques persistants, la mémoire d’agent devient un concept clé à comprendre. Pour les utilisateurs souhaitant anticiper les tendances — agents IA, workflows autonomes, abstraction de chaîne, RWA, PayFi — Phemex propose une plateforme sécurisée et intuitive pour explorer le marché, surveiller les opportunités et affiner ses stratégies de trading.