


Puntos clave
- La memoria de agente es el conjunto de mecanismos que permite a los agentes de IA recordar información a lo largo del tiempo, en lugar de tratar cada interacción como nueva.
- Suele incluir memoria a corto plazo para el contexto actual y memoria a largo plazo para hechos, preferencias y aprendizajes persistentes.
- La memoria de agente puede almacenar preferencias del usuario, reglas del proyecto, errores previos, conocimiento del dominio y resúmenes de ejecuciones anteriores.
- El objetivo no es guardar todo, sino recordar lo importante, recuperarlo cuando sea útil y evitar sobrecargar la ventana de contexto. El reciente anuncio de Cloudflare sobre Agent Memory destaca cómo ayuda a los agentes a "recordar lo que importa" sin saturar el contexto.
- A abril de 2026, la memoria es una capa de diseño fundamental en los sistemas de agentes, con implementaciones activas de Anthropic, el Agents SDK de OpenAI, LangChain y nuevos proveedores de infraestructura.
La inteligencia artificial ha mejorado mucho en razonamiento y uso de herramientas, pero una de las principales limitaciones de muchos agentes sigue siendo básica: olvidan demasiado. Un sistema de IA puede sobresalir en una sola sesión, pero pierde contexto crucial cuando la conversación termina o la tarea se reinicia. Ese es el problema que la memoria de agente busca resolver. Según la documentación de Managed Agents de Anthropic, los almacenes de memoria permiten a los agentes conservar información entre sesiones, como preferencias, reglas del proyecto, errores anteriores y contexto de dominio. La guía de memoria de LangChain indica que la memoria permite a los agentes recordar interacciones previas, aprender de retroalimentación y adaptarse a las preferencias.
A alto nivel, la memoria de agente engloba los sistemas y mecanismos que permiten a un agente de IA retener información útil a lo largo del tiempo, en vez de reiniciar desde cero en cada ejecución. Esta memoria puede incluir el historial reciente de conversación, hechos a largo plazo sobre usuario o proyecto, resúmenes de trabajos previos, lecciones aprendidas y artefactos de razonamiento estructurados. La documentación de Agents SDK de OpenAI diferencia entre el historial de sesión y la memoria de agente persistente, mientras que Anthropic y LangChain enfatizan la importancia de la memoria que sobrevive entre sesiones.
Esto es importante porque la nueva generación de agentes de IA debe hacer más que responder mensajes puntuales. Se espera que gestionen proyectos, coordinen flujos de trabajo, retomen tareas, personalicen decisiones y mejoren con el tiempo. Sin memoria, esta visión se desmorona rápidamente.
¿Qué significa realmente la memoria de agente?
El término puede sonar vago porque "memoria" en IA se usa de varias maneras. En el contexto de agentes, no se trata simplemente de una ventana de contexto más grande. Suele combinar almacenamiento, recuperación, resumen y recordatorio para ayudar a preservar información útil entre tareas o sesiones. Según Anthropic, cada sesión de Managed Agents comienza desde cero y olvida lo aprendido al finalizar, pero los almacenes de memoria permiten conservar información entre sesiones. LangChain conceptualiza la memoria como un sistema que recuerda interacciones pasadas para que los agentes puedan aprender y adaptarse.
Esta distinción es clave: una ventana de contexto más grande no equivale a memoria real. La ventana de contexto solo contiene lo que se pasa actualmente al modelo. La memoria de agente suele ser externa, persistente y selectiva. Los documentos de sandbox-agent de OpenAI indican que la memoria es distinta del historial de sesión y destila enseñanzas en archivos del espacio de trabajo. El anuncio de Agent Memory de Cloudflare señala que su sistema extrae información de conversaciones y la pone a disposición cuando es relevante, en vez de cargar todo en el contexto.
Por qué importa la memoria de agente
La memoria de agente es relevante porque la mayoría de las tareas útiles no son de una sola vez.
Si un agente de IA ayuda en investigación, trading, programación, operaciones o soporte, necesita continuidad. Es posible que deba recordar:
- Objetivos del usuario
- Decisiones previas
- Errores cometidos anteriormente
- Formatos preferidos
- Estado actual del proyecto
- Hechos que sería costoso redescubrir
La documentación de Anthropic menciona preferencias, reglas del proyecto, errores previos y contexto del dominio como ejemplos de lo que los agentes deben trasladar entre sesiones. LangChain indica que la memoria es crucial a medida que los agentes abordan tareas más complejas y repiten interacciones.
Sin memoria, los agentes tienden a:
- Repetir las mismas preguntas
- Olvidar instrucciones
- Perder la continuidad del proyecto
- Desperdiciar tiempo reconstruyendo el contexto
Cloudflare apunta que una memoria persistente ayuda a que los agentes mejoren con el tiempo al recordar lo importante y olvidar lo irrelevante. La investigación reciente de Anthropic, informada por Business Insider, también explora sistemas que revisan el comportamiento pasado entre sesiones para identificar patrones y perfeccionar el rendimiento futuro.
Para los usuarios, esto significa mayor continuidad. Para los desarrolladores, menos sobresaturación de prompts y flujos de trabajo menos frágiles. Para el ecosistema, la diferencia entre agentes meramente reactivos y agentes capaces de acumular experiencia.
Memoria de agente de IA (fuente)
Memoria de agente vs ventana de contexto
Esta es una de las distinciones más importantes.
La ventana de contexto es el texto o input multimodal que el modelo ve en ese momento. Es transitoria y limitada. La memoria de agente es información guardada fuera del contexto activo, que se recupera o resume cuando es necesaria.
El artículo de Anthropic sobre context engineering enfatiza que el contexto es un recurso finito y debe ser seleccionado cuidadosamente. El anuncio de Cloudflare sobre Agent Memory refuerza la idea: la memoria debe hacer disponible información importante sin saturar la ventana de contexto.
Esto implica compresión y selectividad. No se busca recordar todo, sino lo relevante en el momento adecuado. El "cookbook" de OpenAI sobre memoria y compactación muestra cómo los agentes pueden ser más fiables usando patrones de almacenamiento a largo plazo en vez de mantener toda la evidencia en el prompt activo.
Tipos principales de memoria de agente
Cada framework usa términos distintos, pero las categorías generales son claras.
Memoria a corto plazo
Normalmente se refiere a información relevante para la conversación, tarea o ciclo actual. La guía de LangChain trata la memoria en función del alcance del recuerdo, y un artículo reciente de Neo4j la considera uno de los tres tipos principales.
Incluye:
- Turnos recientes de conversación
- Salidas de herramientas en esta ejecución
- Notas temporales
- Planes intermedios
Esto se parece al “estado de sesión”, aunque en sistemas avanzados puede resumirse o compactarse según evoluciona la tarea. La documentación de Agents SDK de OpenAI describe los "session stores" como almacenamiento del historial de conversación de la sesión, un patrón clásico de memoria a corto plazo.
Memoria a largo plazo
Es lo que la mayoría entiende como memoria persistente. Los almacenes de memoria de Anthropic están diseñados para esto: conservar preferencias, reglas, errores y contexto de dominio entre sesiones. Cloudflare lo ve como una forma de que los agentes recuerden información importante con el tiempo.
Puede incluir:
- Preferencias del usuario
- Información de fondo del proyecto
- Conclusiones previas
- Conocimiento reutilizable
- Instrucciones recurrentes
- Hechos duraderos
Esto contribuye a que el agente no sea "sin estado" entre usos repetidos.
Memoria de razonamiento
Algunos sistemas distinguen una tercera categoría: memoria sobre el propio proceso de pensamiento, lecciones y heurísticas del agente. Neo4j la llama "memoria de razonamiento". OpenAI también se orienta a esta idea al describir la memoria como lecciones destiladas de ejecuciones anteriores.
Puede incluir:
- Estrategias que funcionaron
- Errores a evitar
- Patrones de descomposición
- Notas de mejora personal
Esto permite ir más allá de "recordar preferencias": es recordar cómo operar mejor la próxima vez.
¿Qué puede guardar la memoria de agente?
En la práctica, la memoria puede contener diversa información según el diseño del sistema.
Anthropic ofrece ejemplos claros:
- Preferencias del usuario
- Reglas del proyecto
- Errores previos
- Contexto del dominio
OpenAI describe la memoria como lecciones destiladas, incluyendo:
- Aprendizajes específicos de tareas
- Resúmenes compactados
- Conocimiento reutilizable
Cloudflare la enfoca como recuerdo selectivo, sugiriendo que los sistemas pueden almacenar:
- Lo relevante
- Lo que debe olvidarse
- Lo que se mostrará después
LangChain señala que los agentes pueden recordar:
- Interacciones previas
- Preferencias del usuario
- Patrones de retroalimentación
Cómo funciona la memoria de agente
No existe una arquitectura universal, pero la mayoría sigue este patrón:
- Capturar información útil de interacciones o ejecuciones.
- Almacenar en una estructura persistente.
- Recuperar fragmentos relevantes al comenzar una nueva tarea.
- Inyectar o referenciar esa memoria en el ciclo activo.
- Actualizar la memoria al finalizar la tarea o surgir nuevos aprendizajes.
Anthropic describe la memoria persistente como algo que el agente transporta entre sesiones. OpenAI la documenta como archivos del espacio de trabajo que futuras ejecuciones pueden consultar. Cloudflare extrae información de conversaciones y la pone disponible después.
Esto significa que la memoria suele ser parte base de datos, parte capa de recuperación y parte de resumen. Algunos sistemas usan archivos estructurados, otros embeddings y búsqueda vectorial. Algunos la organizan jerárquicamente. Lo importante es que los sistemas modernos buscan que la memoria sea estructurada y consultable, no solo un archivo de texto antiguo.
Memoria de agente en frameworks actuales
Anthropic
La documentación de Managed Agents de Anthropic describe la memoria de agente como un sistema para transportar información entre sesiones; sin ella, cada sesión es "en blanco". La integración SDK también menciona una interfaz de memoria estructurada para Claude. El trabajo reciente sobre "dreaming" explora cómo los agentes revisan comportamiento anterior y mejoran el futuro, viendo la memoria como vía de mejora reflexiva.
OpenAI
La documentación pública de Agents SDK enfatiza que los agentes mantienen suficiente estado para completar tareas en varios pasos. Hace distinción entre memoria de sesión conversacional y memoria persistente tipo sandbox. El "cookbook" de memoria y compactación sugiere que un diseño fiable depende de controlar y comprimir la memoria, no solo de almacenar más.
LangChain
La guía de memoria la define como un sistema para recordar interacciones previas, aprender de retroalimentación y adaptarse a las preferencias. Es una capa conceptual que gana importancia con tareas e interacciones más complejas.
Cloudflare
El anuncio de Agent Memory en abril de 2026 lo presenta como servicio gestionado. El enfoque es ayudar a los agentes a recordar lo importante sin saturar ventanas de contexto, reflejando el cambio del sector hacia sistemas de memoria selectiva.
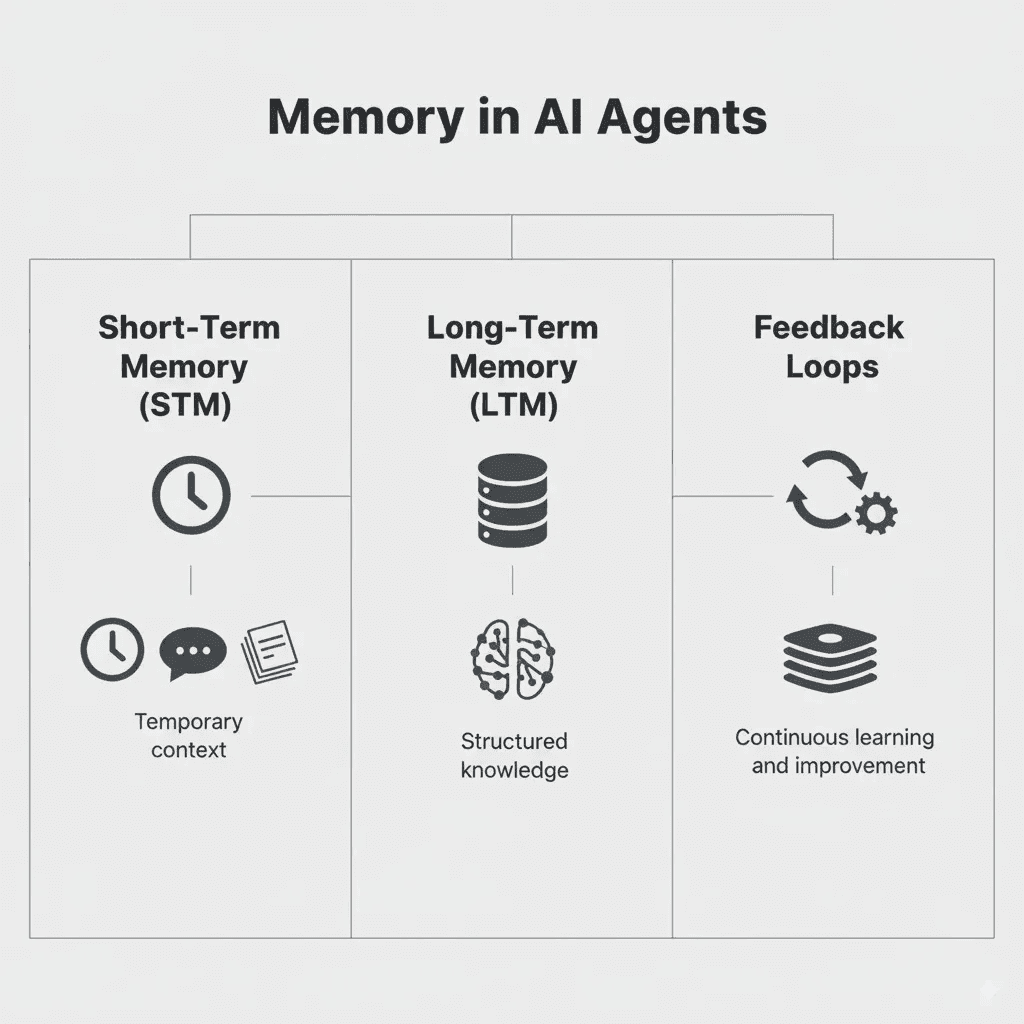
Tipos de memoria de agente de IA (fuente)
Por qué es difícil la memoria de agente
Aunque suena simple, es difícil en la práctica.
No todo debe recordarse: un buen sistema debe decidir qué conservar. Guardarlo todo hace que la recuperación sea ruidosa y costosa; guardar poco, deja al agente "olvidadizo". Cloudflare resume este reto: "recuerda lo que importa, olvida lo que no".
No toda memoria debe recuperarse siempre: hasta los recuerdos útiles solo lo son si se presentan en el momento adecuado. Anthropic enfatiza que el contexto es finito y debe seleccionarse. Recordar demasiada información puede ser tan problemático como recordar poca.
La memoria puede quedar obsoleta o ser errónea: si cambian las preferencias del usuario o el rumbo del proyecto, los recuerdos antiguos pueden perjudicar. Anthropic ha destacado la importancia del control del usuario sobre la memoria: visibilidad, edición y deshabilitación.
El diseño de la memoria afecta la seguridad: una mala arquitectura puede reforzar supuestos erróneos, filtrar información sensible o conservar datos que debieron eliminarse. En el sector de consumo, se han planteado preocupaciones sobre privacidad y efectos psicológicos no intencionados, aunque esto va más allá de los agentes específicamente.
Beneficios de la memoria de agente
Pese a los retos, la memoria puede mejorar significativamente la calidad de los agentes.
Mayor continuidad: los agentes dejan de ser repetitivos. Anthropic lo ilustra con ejemplos como reglas del proyecto y errores previos.
Mejor personalización: al recordar preferencias y contexto, los agentes se adaptan con el tiempo, sin re-aprender lo básico cada sesión. LangChain lo menciona explícitamente.
Eficiencia: si el agente ya conoce el contexto relevante, emplea menos recursos y tiempo en consultas redundantes. Cloudflare enfatiza evitar sobrecarga en la ventana de contexto.
Fiabilidad: los patrones de memoria compacta de OpenAI sugieren que la memoria ayuda a preservar aprendizajes y evita errores repetidos.
Utilidad a largo plazo: un agente que recuerda un proyecto, no solo un prompt, aporta más en flujos continuos como investigación, codificación o análisis. Así lo plantean Anthropic, LangChain y OpenAI al tratar la memoria como requisito para trabajos de varias sesiones.
Memoria de agente vs generación aumentada por recuperación (RAG)
Otra distinción relevante.
RAG suele referirse a recuperar documentos externos o fuentes de conocimiento relevantes. La memoria de agente significa recordar lo aprendido o almacenado a partir de interacciones previas.
Ambos pueden solaparse, pero no son idénticos. Un agente puede usar RAG para buscar documentos y su memoria para recordar preferencias y errores previos. Tanto OpenAI como Anthropic distinguen la memoria como una capa específica para la continuidad, más allá de la simple búsqueda de documentos.
Por qué la memoria de agente es importante para Crypto y Web3
Para que los agentes de IA sean traders on-chain, operadores de wallets, asistentes de investigación, participantes de gobernanza o actores de comercio A2A, necesitan memoria. Por ejemplo, un agente de trading debe recordar configuraciones de estrategia, errores anteriores y reglas de riesgo. Un agente wallet puede requerir almacenar permisos de usuario o límites recurrentes de gasto. Un agente de investigación autónomo necesita memoria de proyecto para seguir una tesis a lo largo del tiempo.
Esto significa que la memoria de agente es una capa esencial para:
- Billeteras de IA
- Trading autónomo on-chain
- DeFi
- Comercio agente a agente
Conclusión
La memoria de agente es la capa que permite a los sistemas de IA acumular continuidad en vez de reiniciar cada vez.
Incluye contexto de trabajo a corto plazo, conocimientos persistentes y, cada vez más, memoria de razonamiento sobre cómo actuar en el futuro. Anthropic, OpenAI, LangChain y nuevos proveedores la consideran ya una capa de primer nivel en el diseño de agentes.
A medida que los agentes evolucionan de simples interfaces conversacionales a trabajadores digitales permanentes, la memoria de agente se convierte en una de las ideas clave para comprender. Para quienes deseen anticipar tendencias —desde agentes y flujos autónomos hasta abstracción de cadenas, RWAs y PayFi—, Phemex ofrece una plataforma segura y fácil de usar para explorar el mercado, monitorear oportunidades y mejorar su experiencia de trading.