


Wichtigste Erkenntnisse
-
Agenten-Memory bezeichnet Mechanismen, mit denen KI-Agenten Informationen über einen längeren Zeitraum hinweg speichern können, anstatt jede Interaktion als völlig neu zu behandeln.
-
Dies umfasst in der Regel ein Kurzzeitgedächtnis für aktuellen Kontext und ein Langzeitgedächtnis für dauerhafte Informationen wie Präferenzen oder Projektdetails.
-
Agenten-Memory kann Nutzervorlieben, Projektstandards, frühere Fehler, Fachwissen und Zusammenfassungen vorheriger Ausführungen speichern.
-
Ziel ist es, relevante Informationen zu behalten, sie bei Bedarf abzurufen und unnötige Kontextüberladung zu vermeiden. Cloudflares aktuelle Ankündigung zu Agenten-Memory beschreibt dies als „das Erinnern an das Wesentliche“ ohne den Kontext zu überladen.
-
Seit April 2026 wird Memory zu einer zentralen Designebene in Agentensystemen, mit aktiven Lösungen von Anthropic, OpenAI (Agents SDK), LangChain und weiteren Infrastruktur-Anbietern.
Künstliche Intelligenz ist deutlich besser darin geworden, Schlussfolgerungen zu ziehen und Werkzeuge zu nutzen, doch viele Agenten haben weiterhin eine grundlegende Schwäche: Sie vergessen zu viel. Ein herkömmliches KI-System agiert im Rahmen einer Sitzung sehr effizient, verliert aber kritische Informationen, sobald die Konversation endet oder die Aufgabe zurückgesetzt wird. Genau dieses Problem soll Agenten-Memory lösen. Laut Dokumentation von Anthropics Managed Agents ermöglichen Memory-Stores einem Agenten, Informationen wie Präferenzen, Konventionen, Fehler und Kontext über mehrere Sitzungen zu transportieren. Auch LangChains Memory-Anleitung betont, dass Agenten so frühere Interaktionen speichern, aus Feedback lernen und sich anpassen können.
Im Kern beschreibt Agenten-Memory die Systeme und Mechanismen, die es einer KI ermöglichen, nützliche Informationen über Zeiträume hinweg zu speichern, anstatt bei jeder Ausführung wieder bei null zu beginnen. Das umfasst kurzfristige Gesprächsverläufe, langfristige Nutzer- oder Projektinformationen, Zusammenfassungen früherer Arbeiten, Erkenntnisse aus vorangegangenen Ausführungen und sogar strukturierte Argumentationshilfen. Die OpenAI-Dokumentation zum Agents SDK unterscheidet dabei zwischen Gesprächsverlauf (Session History) und langlebigerem Agenten-Memory. Anthropic und LangChain betonen beide die Relevanz von persistentem Memory, das über Sitzungen hinaus Bestand hat.
Das ist relevant, weil die nächste Generation von KI-Agenten mehr können soll, als nur einzelne Anfragen zu beantworten. Sie sollen Projekte begleiten, Workflows koordinieren, laufende Aufgaben überwachen, Entscheidungen personalisieren und sich weiterentwickeln. Ohne Memory scheitert dieses Modell schnell.
Was bedeutet Agenten-Memory konkret?
Der Begriff Memory kann im KI-Kontext verschiedenes bedeuten. Bei Agenten bezieht sich Memory jedoch nicht einfach auf ein größeres Kontextfenster. Gemeint ist meist eine Kombination aus Speicherung, Abruf, Zusammenfassung und gezieltem Erinnern, die einem Agenten hilft, wichtige Informationen über Aufgaben oder Sitzungen hinweg zu bewahren. Laut Anthropics Dokumentation startet jede Managed-Agents-Sitzung standardmäßig frisch und verliert am Ende der Sitzung Gelerntes – Memory-Stores lösen dieses Problem, indem sie Informationen über Sitzungen hinweg sichern. LangChain beschreibt Memory als System, das frühere Interaktionen speichert, sodass Agenten lernen und sich anpassen können.
Das ist wichtig, denn ein größeres Kontextfenster ist kein echtes Gedächtnis. Das Kontextfenster enthält nur das, was aktuell an das Modell übergeben wird. Agenten-Memory ist in der Regel extern, persistent und selektiv. Laut OpenAI ist Memory getrennt vom Sitzungskontext und fasst Erkenntnisse aus vorigen Durchläufen als Dateien im Workspace zusammen. Cloudflare beschreibt Agenten-Memory als System, das relevante Informationen aus Dialogen extrahiert und gezielt verfügbar macht – anstatt alles in den Kontext zu laden.
Warum ist Agenten-Memory wichtig?
Die meisten realen Anwendungsfälle sind keine Einweg-Tasks.
Ob ein KI-Agent bei Recherche, Trading, Codierung, Operationen oder Support hilft – oft ist Kontinuität nötig. Er muss sich zum Beispiel erinnern an:
-
die Ziele des Nutzers,
-
frühere Entscheidungen,
-
gemachte Fehler,
-
bevorzugte Formate,
-
den Stand eines Projekts,
-
oder schwer wiederherzustellende Fakten.
Anthropic nennt explizit Präferenzen, Konventionen, Fehler und Domänenkontext als Beispiele für übergreifende Informationen. LangChain betont, dass Memory essenziell wird, wenn Agenten komplexere Aufgaben und wiederholte Interaktionen übernehmen.
Ohne Memory tendieren Agenten dazu:
-
dieselben Fragen zu wiederholen,
-
Anweisungen zu vergessen,
-
Zusammenhänge zu verlieren,
-
und Zeit mit dem Wiederaufbau von Kontext zu verschwenden.
Cloudflare betont, dass persistentes Memory dazu beiträgt, dass Agenten im Laufe der Zeit smarter werden, indem sie sich an das Wesentliche erinnern. Anthropics „dreaming“-Forschung befasst sich zusätzlich damit, wie Agenten vergangenes Verhalten zwischen Sitzungen reflektieren und daraus Muster für die Zukunft ableiten.
Für Nutzer bedeutet das bessere Kontinuität, für Entwickler weniger komplexe Prompt-Strukturen und robustere Workflows. Insgesamt ist es der Unterschied zwischen reaktiven und wirklich lernenden Agenten.
AI Agent Memory (Quelle)
Agenten-Memory vs. Kontextfenster
Das ist eine der wichtigsten Unterscheidungen.
Ein Kontextfenster umfasst den aktuellen Text oder Input, den das Modell gerade sieht. Es ist temporär und begrenzt. Agenten-Memory ist extern gespeichert und wird bei Bedarf abgerufen oder zusammengefasst.
Anthropics Kontext-Engineering-Artikel betont, dass Kontext ein begrenztes Gut ist und sorgfältig verwaltet werden muss. Cloudflare sieht Memory als Hilfsmittel, relevante Informationen bereitzustellen, ohne das Kontextfenster mit allem bisher Gesehenen zu überladen.
Das bedeutet: Memory ist immer auch eine Frage von Kompression und Selektion. Ziel ist nicht das unendliche Erinnern jedes Details, sondern das gezielte Erinnern relevanter Informationen zur passenden Zeit. OpenAI illustriert dies mit Best-Practices zu „Memory und Kompression“: Agenten werden zuverlässiger, wenn sie Wissen aus früheren Durchläufen strukturiert speichern, statt alles im aktiven Prompt vorzuhalten.
Die Haupttypen von Agenten-Memory
Unterschiedliche Frameworks benutzen abweichende Begriffe, aber die Hauptkategorien zeichnen sich ab.
Kurzzeitgedächtnis
Kurzzeitgedächtnis umfasst meist Informationen zur aktuellen Konversation, aktuellen Aufgabe oder laufenden Ausführungsschleife. Bei LangChain wird Memory teils nach Erinnerungsspanne unterschieden, und Neo4j beschreibt dies als einen von drei Haupttypen von Agenten-Memory.
Kurzzeitgedächtnis kann beinhalten:
-
jüngste Gesprächsbeiträge,
-
aktuelle Tool-Ausgaben,
-
temporäre Notizen,
-
und Zwischenpläne.
Das entspricht am ehesten dem klassischen „Session State“ – in fortschrittlicheren Systemen kann dieser auch zusammengefasst oder verdichtet werden. OpenAI beschreibt Session Stores als Speicher für Gesprächsverläufe einer Sitzung – ein typisches Muster für Kurzzeitgedächtnis.
Langzeitgedächtnis
Langzeitgedächtnis ist meist das, was mit persistentem Memory gemeint ist. Anthropics Memory-Stores sind genau darauf ausgelegt: Präferenzen, Konventionen, Fehler und Domänenkontext über Sitzungen hinweg zu transportieren. Auch Cloudflare fokussiert auf Memory, das über die Zeit hinweg erhalten bleibt.
Langzeitgedächtnis kann beinhalten:
-
Nutzerpräferenzen,
-
Projektkontext,
-
bisherige Schlussfolgerungen,
-
wiederverwendbares Wissen,
-
wiederholte Anweisungen,
-
und dauerhafte Fakten.
Das ist entscheidend, damit ein Agent nicht bei jeder Nutzung „zustandslos“ erscheint.
Reasoning Memory
Einige Systeme differenzieren inzwischen eine dritte Kategorie: das Gedächtnis für eigene Denkprozesse, Lehren und Heuristiken. Neo4j nennt dies Reasoning Memory, getrennt von Kurz- und Langzeitgedächtnis. Auch OpenAI betont diesen Trend, wenn sie Memory als Zusammenfassung von Lernerfahrungen und nicht nur als rohen Verlauf beschreiben.
Reasoning Memory kann beinhalten:
-
bewährte Strategien,
-
Fallstricke zur Vermeidung,
-
Zerlegungsmuster,
-
und Notizen zur Selbstverbesserung.
Das ist relevant, weil Agenten so nicht nur Präferenzen, sondern auch Verbesserungspfade speichern können.
Was kann Agenten-Memory speichern?
In der Praxis hängt der genaue Inhalt vom Systemdesign ab.
Anthropics Dokumentation nennt unter anderem:
-
Nutzerpräferenzen,
-
Projektstandards,
-
gemachte Fehler,
-
und Domänenkontext.
OpenAI beschreibt Memory als destillierte Erkenntnisse vorangegangener Durchläufe; dazu gehören:
-
task-spezifische Erkenntnisse,
-
kompakte Zusammenfassungen,
-
und wiederverwendbares Wissen.
Cloudflare versteht unter Memory gezieltes Erinnern und empfiehlt, zu speichern:
-
was relevant ist,
-
was vergessen werden sollte,
-
und was später benötigt wird.
LangChain schlägt vor, dass Agenten folgendes speichern:
-
frühere Interaktionen,
-
Nutzerpräferenzen,
-
und Feedbackmuster.
Wie funktioniert Agenten-Memory?
Die Architektur ist variabel, folgt aber meist diesem Muster:
-
Erfassen nützlicher Informationen aus Interaktionen oder Durchläufen.
-
Speichern in einer persistenten Struktur.
-
Abrufen relevanter Informationen bei neuen Aufgaben.
-
Einfügen oder Referenzieren der Memory im aktiven Agenten-Loop.
-
Aktualisieren des Memorys bei Aufgabenabschluss oder neuen Erkenntnissen.
Anthropic beschreibt persistente Memory als etwas, das der Agent über Sitzungen hinweg mitführt. OpenAI sieht Memory als Dateien im Workspace, aus denen zukünftige Durchläufe lernen. Auch Cloudflare extrahiert Informationen und macht sie später zugänglich.
Memory-Systeme bestehen typischerweise aus Datenbank-, Abruf- und Zusammenfassungskomponenten. Teilweise werden strukturierte Dateien, Vektor-Suchsysteme oder hierarchische Strukturen genutzt. Wichtig ist: Moderne Memory-Systeme sollen strukturiert und abfragbar sein – nicht nur reine Textarchive.
Agenten-Memory in aktuellen Frameworks
Anthropic
Anthropics Managed-Agents-Dokumentation bietet eine der klarsten öffentlichen Definitionen: Memory-Stores erlauben Agenten, Informationen über Sitzungen hinweg zu speichern; ohne sie startet jede Sitzung neu. Die SDK-Integration für Claude erwähnt zudem ein strukturiertes Memory-Tool-Interface.
Anthropics „dreaming“-Forschung (Mai 2026) geht noch weiter und untersucht, wie Agenten vergangenes Verhalten zwischen Sitzungen analysieren und die Leistung verbessern können.
OpenAI
OpenAIs Agents SDK betont, dass Agenten genug Status behalten, um mehrstufige Aufgaben zu erfüllen. Die Memory-Komponenten unterscheiden zwischen Sitzungsspeicher und persistentem Sandbox-Agent-Memory. Letztere bestehen aus Dateien, die aus früheren Durchläufen gelernt werden. OpenAIs Empfehlungen legen zudem Wert auf Memory-Kompression und gezieltes Management.
LangChain
LangChain beschreibt Memory als System, das frühere Interaktionen speichert, damit Agenten Feedback aufnehmen und sich an Nutzer anpassen können. Je anspruchsvoller die Aufgaben, desto wichtiger ist die Memory-Komponente.
Cloudflare
Cloudflare wirbt mit Agenten-Memory als Managed Service. Ziel ist es, Agenten das Behalten relevanter Informationen zu ermöglichen, ohne das Kontextfenster zu überladen. Das entspricht dem Trend hin zu selektiven statt vollständigen Memory-Systemen.
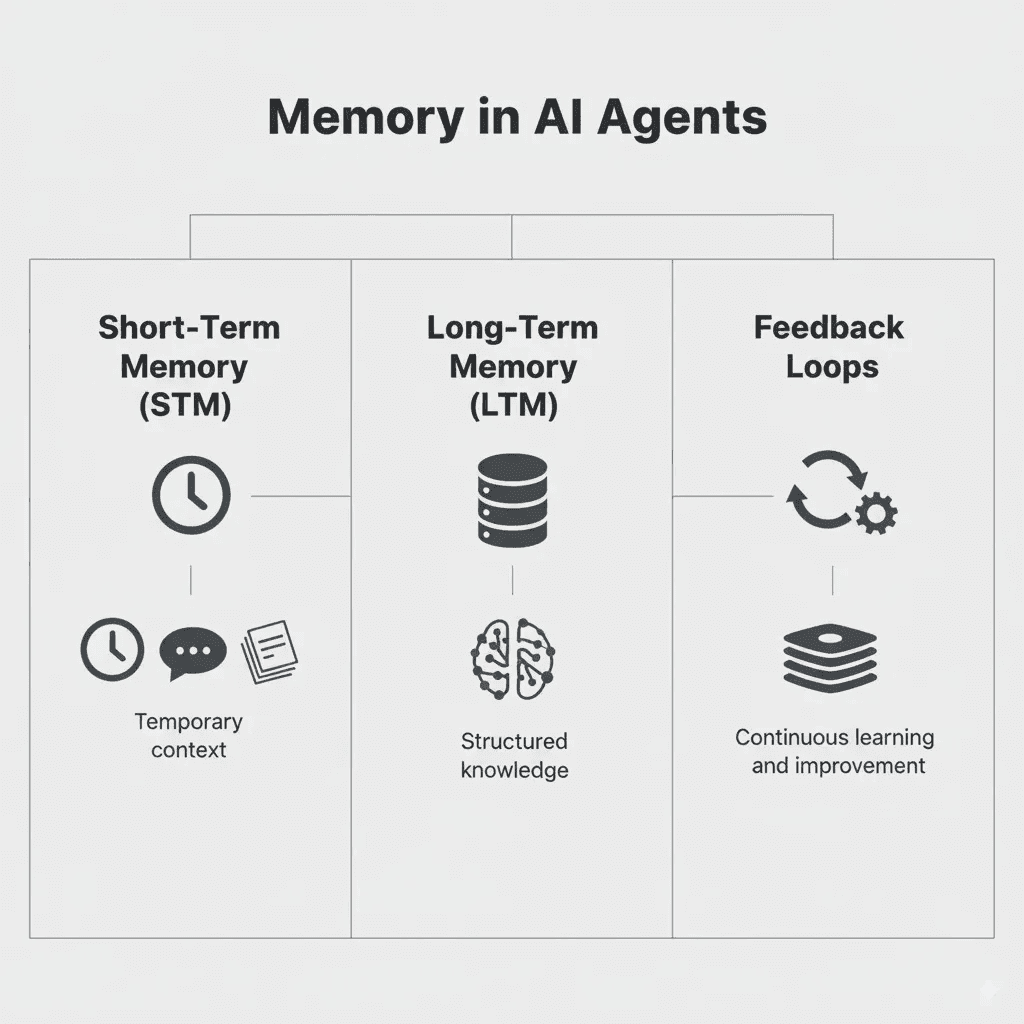
Typen von AI-Agenten-Memory (Quelle)
Warum ist Agenten-Memory herausfordernd?
Theorie und Praxis klaffen auseinander.
Nicht alles sollte gespeichert werden – Gute Systeme müssen entscheiden, was relevant ist. Wird alles gespeichert, wird der Abruf ineffizient. Zu wenig – der Agent bleibt vergesslich. Cloudflares „nur das Wesentliche speichern“ bringt es auf den Punkt.
Nicht jede Erinnerung ist immer relevant – Auch nützliche Erinnerungen müssen zum richtigen Zeitpunkt bereitgestellt werden. Zu viel kann die Leistung beeinträchtigen.
Memory kann veralten oder falsch werden – Ändern sich Präferenzen oder Projektrichtung, können alte Erinnerungen hinderlich sein. Transparenz, Bearbeitbarkeit und Deaktivierbarkeit von Memory sind daher wichtig.
Memory-Design betrifft auch Sicherheit – Schlecht designte Memory kann Annahmen verstärken, sensible Infos preisgeben oder Unnötiges bewahren. Privatsphäre und psychologische Auswirkungen werden häufig diskutiert, auch wenn dies über Agenten hinausgeht.
Vorteile von Agenten-Memory
Trotz Herausforderungen bietet Agenten-Memory große Mehrwerte:
Bessere Kontinuität – Agenten wirken weniger statisch und repetitiv. Beispiele wie Projektkonventionen und Fehler verdeutlichen das.
Bessere Personalisierung – Präferenzen und Kontext werden gespeichert, sodass Agenten sich langfristig besser anpassen können.
Bessere Effizienz – Agenten müssen weniger Kontext neu etablieren und weniger redundante Nachfragen stellen. Cloudflare hebt hervor, wie Memory Kontextüberladung verhindert und effizienter macht.
Mehr Zuverlässigkeit – OpenAI zeigt, wie Memory durch Wiederverwendung von Erkenntnissen aus früheren Durchläufen Fehler wiederholt vermeiden hilft.
Langfristiger Nutzen – Agenten, die ganze Projekte begleiten und nicht nur Einzelanfragen, bieten Mehrwert für laufende Workflows in Forschung, Coding, Analyse oder Betrieb.
Agenten-Memory vs. Retrieval-Augmented Generation
Ein wichtiger Unterschied:
RAG beschreibt meist das Abrufen externer Dokumente/Wissensquellen zu einer Anfrage. Agenten-Memory hingegen speichert und ruft Wissen auf, das der Agent in früheren Interaktionen gelernt oder destilliert hat.
Beides kann kombiniert werden, ist aber nicht dasselbe. Ein Agent kann RAG für externe Quellen und Memory für Nutzerpräferenzen und Fehler nutzen. OpenAI und Anthropic dokumentieren dies durch ihre Unterscheidung von Memory als persistente Kontinuitäts-Schicht und reiner Dokumentensuche.
Bedeutung für Krypto und Web3
Wenn KI-Agenten als Onchain-Trader, Wallet-Operatoren, Recherchehilfen oder Teilnehmer am Governance-Prozess agieren sollen, ist Memory unverzichtbar. Ein Trading-Agent muss Strategien, Fehler und Risikoregeln erinnern können. Ein KI-Wallet muss Berechtigungen oder Ausgabenlimits speichern. Ein Forschungsagent benötigt Projekt-Memory, um seine Thesen zu verfolgen.
Das macht Agenten-Memory zur Basis für:
-
KI-Agent-Wallets,
-
autonome Onchain-Trades,
-
DeFi-Systeme,
-
und Agent-zu-Agent-Kommunikation.
Fazit
Agenten-Memory ermöglicht es KI-Systemen, Kontinuität zu entwickeln, statt jedes Mal neu zu beginnen.
Es umfasst kurzfristigen Arbeitskontext, langfristiges Wissen und zunehmend Reasoning-Memory, also das Speichern von Verbesserungspfaden. Anthropic, OpenAI, LangChain und weitere Anbieter behandeln Memory mittlerweile als zentrales Designelement.
Mit der Weiterentwicklung der KI-Agenten zu dauerhaften digitalen Arbeitskräften wird Agenten-Memory zu einem Schlüsselfaktor. Wer sich über neue Entwicklungen rund um KI-Agenten, autonome Workflows, Chain-Abstraktion, RWAs und PayFi informieren möchte, findet bei Phemex eine professionelle und sichere Plattform, um den Markt zu erkunden und neue Chancen zu beobachten.