
主なポイント
AIエージェントレジストリは、ソフトウェアエージェントを登録・識別・発見するためのシステムであり、ユーザーやアプリケーション、他のエージェントが容易に検索・連携できるように設計されています。Fetch.aiのドキュメントでは、Agentverseをエージェント登録と発見のためのプラットフォームと説明しており、Almanacによりエージェントやトランザクションのオープンレジャー(台帳)も参照されています。
実際には、エージェントレジストリはエージェントそのものではなく、エージェントの名称、エンドポイント、機能、識別情報、対応プロトコル、稼働状況などのメタデータを格納します。これは、現行のエージェントエコシステムにおける登録・発見プラットフォームの説明から推測されます。
エージェントレジストリは、どのエージェントがどのタスクを実行でき、信頼できるかという基本的な疑問にソフトウェアが答えるために重要です。Fetch.aiは登録と発見性を明確に結びつけており、NEARのShade Agentsは登録と有効性・証明を関連付けています。
レジストリによっては、主に発見やマーケットでの可視性に重点を置くものもあれば、検証や証明、パーミッション、オンチェーンIDも扱うものもあります。AgentverseとNEARのShade Agentsが、この2つの設計例です。
AIエージェントが高度化するにつれて、構築方法だけでなく「どう見つけるか、識別するか、検証するか、連携するか」が次なる課題となります。これは根本的なインフラ課題であり、異なるプラットフォーム上に何千・何百万というエージェントが存在する未来では、ユーザーやシステムが「どのエージェントが気象データを扱うのか」「どれがオンチェーン活動を分析できるのか」「どれが稼働中か」「どれが検証済みか」「どのプロトコルに対応しているか」などを知る方法が必要です。
この課題を解決するのがAIエージェントレジストリです。ドメイン名システムがウェブサイトの発見を助け、アプリストアがソフトウェアを発見するのと同様に、エージェントレジストリは人やマシンが適切なエージェントを見つけるインフラとなります。Fetch.aiのドキュメントでは、Agentverseを登録・検索・発見のための開発プラットフォームと明記し、ネットワークスタックの一部としてエージェントと取引のオープンレジャーも挙げています。
AIエージェントレジストリの実態
AIエージェントレジストリは、エージェントに関する情報を記録する仕組みであり、他者がエージェントを発見・参照し、場合によっては検証できるようにします。
重要なのは、レジストリ自体はエージェント本体ではないことです。レジストリは、エージェントを取り巻く情報レイヤーです。主な内容には、
- エージェント名または識別子
- エンドポイントやアドレス
- 対応プロトコル
- サポートする機能・タスクカテゴリ
- アイデンティティやウォレット情報
- 稼働状況や有効性
- 証明や検証情報
- コード・マーケットリスト・決済手段へのリンク
Fetch.aiのドキュメントでは、Agentverseをホスティングと登録のプラットフォーム、Almanacを公開コントラクトと説明しています。これはレジストリの機能を示しており、エージェントが登録され、他者が存在と到達手段を認識できる場所です。エージェントレジストリは、シンプルなディレクトリから厳格な信頼基盤まで多様です。
AIエージェントにレジストリが必要な理由
エージェントエコノミーにおいてレジストリがないと発見性が損なわれ、混乱を招きます。金融、リサーチ、カスタマーサービス、ゲーム、ロジスティクス、ブロックチェーンインフラなど多様な分野でエージェントが拡大する未来では、ユーザーやアプリが個々のアドレスやプロトコル、機能を把握するのは現実的ではありません。
レジストリは複数の実用的課題を解決します。第一は発見性です。ユーザーや他のエージェントが、誰が作ったかやどこで稼働しているかを知らずとも関連エージェントを見つける必要があります。Fetch.aiのAgentverseは、AIエージェントのマーケットプレイスかつオープンなディレクトリとして設計されています。
第二はアイデンティティです。レジストリはエージェントにエコシステム内で認識される存在感を与えます。ウォレットやコントラクトもエージェント相互作用の枠組みに組み込まれており、Coinbaseのx402などではウォレットベースのIDが重要性を増しています。
第三は信頼性です。レジストリには存在の有無だけでなく、有効性・検証・正規コード実行などの情報も含められます。NEARのShade Agentドキュメントでは、証明や測定基準を満たし登録が有効な場合のみ「有効」となります。
第四は相互運用性です。エージェントが連携するには、機能や対応プロトコルを共通の方法で識別する必要があります。ASI:OneのAgent Chat Protocolは、構造化されたエージェント間通信を標準化する一例であり、どの通信規格に対応しているかもレジストリで明示できます。
エージェントレジストリの主な情報項目
レジストリの設計は様々ですが、ほとんどの場合、識別情報・機能・信頼に関するメタデータを含みます。基本は一意なID(コントラクトアドレス、ウォレットアドレス、アカウントIDなど)です。
次にエンドポイント情報(APIエンドポイント、コントラクトアドレス、MCP対応インターフェース、マーケットリストなど)があります。
その次は機能情報です。例えばテキスト要約、天気取得、ブロックチェーン検索、取引執行、リスク分析など、レジストリはエージェントの機能を表現できる必要があります。Fetch.aiのAgentverseは検索・ランキング・可視化ツールでこの方向性を示しています。
さらに強化されたレジストリでは、
- 検証済みか
- 有効な証明を提出しているか
- 稼働中か
- 発行者や管理者は誰か
- 利用・評価履歴があるか
といった信頼メタデータも含まれます。
つまり、レジストリはエージェントを孤立したソフトウェアから、ネットワーク内で検索可能な存在へと変えます。
発見型レジストリと検証型レジストリ
レジストリは大きく2つのモデルに分けられます。1つは「発見型レジストリ」で、主に人やマシンが有用なエージェントを見つける役割です。Agentverseはこのモデルに当てはまります。登録・検索・可視化・マーケット展開を担うプラットフォームです。
2つ目は「検証型レジストリ」で、有効なエージェントのみが特定システムと連携できるようにするものです。NEARのShade Agentコントラクトが好例で、登録には証明やポリシーチェックが必須であり、有効登録エージェントだけが保護されたメソッドを利用できます。
将来的に両者を組み合わせるエコシステムが増えると予想されます。取引や処理が増える中、レジストリは単なるリスト以上の役割を担うようになります。
エージェントレジストリの運用例
実際のレジストリ運用はシンプルなライフサイクルに従います。まず開発者や運営者がエージェントを登録(コンソール、マーケットダッシュボード、SDK、スマートコントラクトメソッドなど)。Fetch.aiやNEARのドキュメントもこれを示しています。
次に、レジストリがエージェントのメタデータを保存します。設計によりデータベース、オンチェーンコントラクト、ハイブリッド型などがあります。
その後、エージェントは他者から発見・呼出し可能に。発見重視のAgentverseでは検索や可視化、トラフィック増加、信頼重視のShade Agentsでは保護処理への参加資格などが得られます。
さらに、レジストリは動的に更新される場合も。エージェントがオフライン化、検証失効、期限切れ、アップグレードされた場合などに状態変更されます。Web3系では公開台帳やコントラクト記録でプログラム的な状態検査がしやすいメリットがあります。
各実装は異なりますが、共通点は「エージェントの存在と属性に共通参照点を与える」という点です。
暗号資産分野でのレジストリの重要性
暗号資産システムは、IDや価値移転、プログラム的な連携がオープンプロトコルで行われる前提のため、エージェントレジストリが特に重要となります。
エージェントがウォレット管理、トランザクション署名、スマートコントラクト呼出し、有料API利用、他のオンチェーンサービスとの連携を行う場合、レジストリは市場インフラの一部となります。Web3において、
- ウォレットやアプリに発見されやすい
- スマートコントラクトで検証可能
- マシンネイティブな決済プロトコルで支払い可能
- 互換性のあるエージェントとのマッチング
- チェーンや環境を跨いだ追跡
が可能となり、レジストリはエージェントマーケット、決済プロトコル、通信標準と自然に連携します。エージェントが経済活動を行い始めると、レジストリは単なるリストではなく、デジタル商取引のインフラとなります。
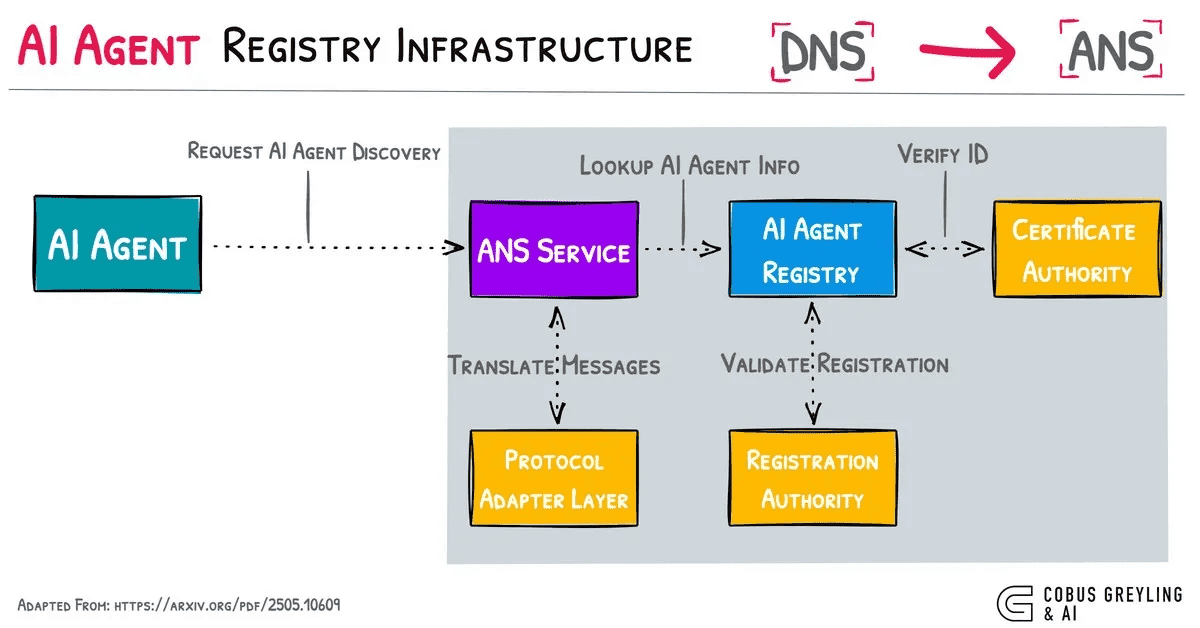
AIエージェントレジストリとエージェントマーケットプレイスの違い
両者は関連しますが異なります。エージェントレジストリは識別・発見レイヤーで、エコシステムにどのエージェントが存在し、どこで見つけられるかを示します。エージェントマーケットプレイスは商業・ユーザー向けレイヤーで、ユーザーにエージェントサービスの閲覧・比較・評価・利用を支援します。
成熟したエコシステムでは両者が密接に連携しますが、レジストリはより基盤的レイヤーです。レジストリなしにスケーラブルなマーケットは成立しません。
主なリスクと課題
エージェントレジストリは便利ですが、適切に設計しなければなりません。第一のリスクはスパムや低品質エージェントの氾濫です。登録が容易すぎると、レジストリが信頼できなくなります。
第二は偽の信頼シグナルです。レジストリで存在が確認できても、能力や安全性、誠実性は保証されません。検証レイヤーが支援しますが、品質や評判は依然課題です。
第三は断片化です。各エコシステムが独自レジストリを構築すると、相互運用性が損なわれます。複数レジストリ時代には共通スキーマや橋渡し標準が必要です。
第四は中央集権化の圧力です。分散的エコシステムでも大手の発見ハブに依存しやすく、アプリストア型の権力集中がエージェント分野でも起き得ます。
第五は古いデータの放置です。エージェントが利用不可や挙動変更・安全性低下してもレジストリに残る場合、鮮度維持の仕組みが不可欠です。
エージェント経済インフラとしてのレジストリ
レジストリが重要な理由は、「AIツール」から「エージェント経済」への進化を象徴する基礎的インフラの1つであるためです。
真のエージェント経済では、発見可能性・識別性・相互運用性・支払い性・検証性のすべてが求められます。レジストリはすべてに関わる最初のインフラであり、エージェント同士がユーザーだけでなく互いに連携し始める際に不可欠です。
このため、現行エコシステムはこれらの層に投資を開始しています。Fetch.aiは発見性とオープンレジャー、NEARは証明付き登録、Agent Chat Protocolのような標準化も進展中です。これらはエージェントが経済主体となるためのスタック形成の初期段階を示しています。
まとめ
AIエージェントレジストリは、ソフトウェアエージェントの登録・識別・発見を行うシステムです。最も単純にはディレクトリですが、発展的にはエージェント経済の信頼・ID・検証レイヤーとしても機能します。
エージェントが自律化する中で、「このエージェントは誰か・何ができるか・どこに存在するか・信頼できるか」という重要な疑問に答える仕組みが必要です。現在のエコシステムでは、Fetch.aiのAgentverseのような発見重視型とNEARのShade Agent契約のような信頼重視型の2モデルが登場しています。
この概念はまだ初期段階ですが、今後AIエージェントがデジタル市場の主要な参加者となるため、レジストリはシステム利用性を支えるインフラの中心となるでしょう。