


Key Takeaways
Agent memory is the set of mechanisms that lets AI agents remember information across time instead of treating every interaction as brand new.
It usually includes short-term memory for current context and long-term memory for persistent facts, preferences, and lessons.
Agent memory can store items such as user preferences, project conventions, prior mistakes, domain knowledge, and summaries of previous runs.
The goal is not to save everything forever, but to remember what matters, retrieve it when useful, and avoid overloading the context window. Cloudflare’s recent Agent Memory announcement frames this as helping agents “recall what matters” without filling up context.
As of April 2026, memory is becoming a major design layer in agent systems, with active implementations from Anthropic, OpenAI’s Agents SDK, LangChain, and newer infrastructure providers.
Artificial intelligence has become much better at reasoning and using tools, but one of the biggest limitations of many agents is still surprisingly basic: they forget too much. A normal AI system can be excellent inside a single session, then lose critical context as soon as the conversation ends or the task resets. That is the problem agent memory is designed to solve. Anthropic’s Managed Agents docs describe memory stores as a way for agents to carry information across sessions, including user preferences, project conventions, prior mistakes, and domain context. LangChain’s memory guide similarly says memory lets AI agents remember previous interactions, learn from feedback, and adapt to user preferences.
At a high level, agent memory means the systems and mechanisms that let an AI agent retain useful information over time instead of restarting from zero every time it runs. That memory can include short-term conversation history, long-term facts about a user or project, summaries of prior work, lessons learned from earlier runs, and even structured reasoning artifacts. OpenAI’s Agents SDK docs distinguish between session history and longer-lived agent memory, while Anthropic and LangChain both emphasize persistent memory that survives across sessions.
This matters because the next generation of AI agents is supposed to do more than answer one-off prompts. They are expected to run projects, coordinate workflows, revisit ongoing tasks, personalize decisions, and improve over time. Without memory, that vision breaks down quickly.
What Does Agent Memory Actually Mean?
The term can sound vague, because memory in AI is used in several different ways. In the context of agents, memory does not simply mean a larger context window. It usually means some combination of storage, retrieval, summarization, and recall that helps an agent preserve useful information across tasks or sessions. Anthropic’s docs say that by default each Managed Agents session starts fresh and loses what it learned when the session ends, while memory stores solve that by preserving information across sessions. LangChain’s guide makes the same distinction in more conceptual terms, describing memory as a system that remembers previous interactions so agents can learn and adapt.
That distinction matters because a bigger context window is not the same as real memory. A context window only holds what is currently passed into the model. Agent memory is usually externalized, persistent, and selective. OpenAI’s sandbox-agent docs say memory is separate from session conversation history and distills lessons from prior runs into files in the sandbox workspace. Cloudflare’s Agent Memory announcement describes its system as extracting information from agent conversations and making it available when needed, rather than just shoving everything into the context window.
Why Agent Memory Matters
Agent memory matters because most useful tasks are not truly one-shot.
If an AI agent is helping with research, trading, coding, operations, or customer support, it often needs continuity. It may need to remember:
the user’s goals,
earlier decisions,
mistakes it made last time,
preferred formats,
ongoing project state,
or facts that are expensive to rediscover repeatedly.
Anthropic’s memory-store docs explicitly list user preferences, project conventions, prior mistakes, and domain context as examples of what agents may need to carry across sessions. LangChain says memory becomes crucial as agents tackle more complex tasks and repeated user interactions.
Without memory, agents tend to:
repeat the same questions,
forget instructions,
lose project continuity,
and waste time rebuilding context.
Cloudflare’s recent write-up says persistent memory helps agents get smarter over time by recalling what matters and forgetting what does not. Anthropic’s recent “dreaming” research direction, as reported by Business Insider, also points toward systems that review past behavior between sessions to identify patterns and refine future performance.
For users, this means better continuity. For developers, it means less prompt stuffing and less fragile workflow design. For the broader AI-agent ecosystem, it means the difference between agents that are merely reactive and agents that can actually accumulate experience.
Agent Memory vs Context Window
This is one of the most important distinctions in the whole topic.
A context window is the active text or multimodal input the model sees right now. It is transient and bounded. Agent memory is information saved outside the live context, then retrieved or summarized back into the agent when needed.
Anthropic’s context-engineering article emphasizes that context is a finite resource and must be curated carefully. Cloudflare’s Agent Memory announcement makes essentially the same point from a product perspective: memory should make important information available without filling the context window with everything the agent has ever seen.
That means memory is partly about compression and selectivity. The goal is not infinite recall of every detail. The goal is a useful recall of the right details at the right time. OpenAI’s “memory and compaction” cookbook reinforces this idea by showing how more reliable agents can use compaction and longer-term storage patterns rather than keeping all evidence live in the active prompt.
The Main Types of Agent Memory
Different frameworks use slightly different language, but the broad categories are becoming clearer.
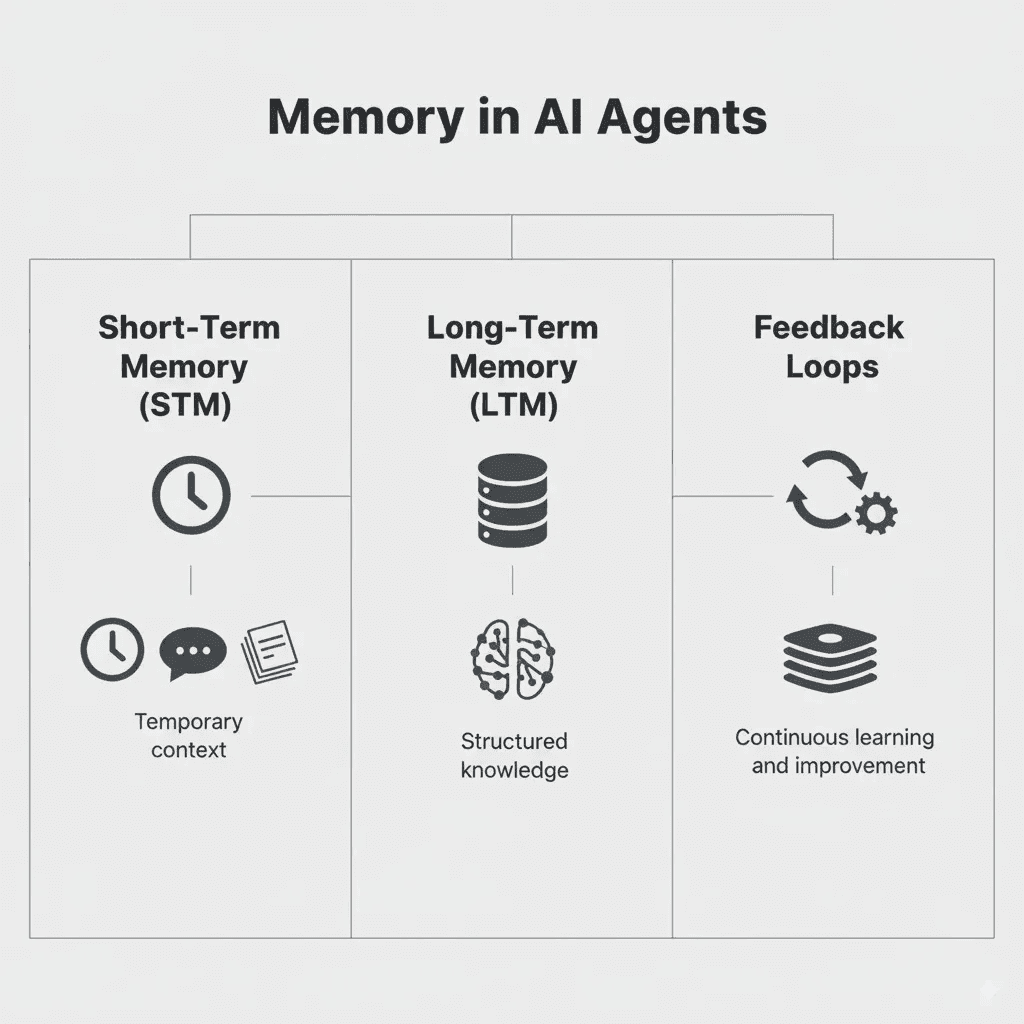
Short-Term Memory
Short-term memory usually means information relevant to the current conversation, current task, or current execution loop. LangChain’s conceptual guide treats memory partly in terms of recall scope, and Neo4j’s recent developer article on agent memory calls this one of the three major memory types.
Short-term memory can include:
recent conversation turns,
tool outputs from this run,
temporary working notes,
and intermediate plans.
This is closest to ordinary “session state,” though in more advanced systems it may still be summarized or compacted as the task evolves. OpenAI’s Agents SDK docs describe session stores as preserving conversation history for a given session, which is a classic short-term-memory pattern.
Long-Term Memory
Long-term memory is what most people mean when they talk about persistent memory. Anthropic’s memory stores are designed for exactly this: carrying preferences, conventions, prior mistakes, and domain context across sessions. Cloudflare’s Agent Memory announcement similarly positions persistent memory as a way for agents to remember what matters over time.
Long-term memory can include:
user preferences,
project background,
prior conclusions,
reusable knowledge,
recurring instructions,
and durable facts.
This is what helps an agent stop feeling stateless across repeat use.
Reasoning Memory
Some systems are now distinguishing a third category: memory of the agent’s own thought process, lessons, and heuristics. Neo4j’s agent-memory article calls this reasoning memory, separate from short-term and long-term memory. OpenAI’s sandbox-agent memory docs also move in this direction by describing memory as distilled lessons from prior runs rather than just raw history.
Reasoning memory can include:
strategies that worked before,
pitfalls to avoid,
decomposition patterns,
and self-improvement notes.
This is a big deal because it points beyond “remember my preferences” toward remember how to operate better next time.
What Agent Memory Can Store
In practice, agent memory can hold many kinds of information, depending on the system design.
Anthropic’s docs give some of the clearest concrete examples:
user preferences,
project conventions,
prior mistakes,
and domain context.
OpenAI’s sandbox-agent docs describe memory as distilled lessons from prior runs, which implies:
task-specific learnings,
compressed summaries,
and reusable working knowledge.
Cloudflare’s announcement frames memory as selective recall, suggesting systems may store:
what matters,
what should be forgotten,
and what should be surfaced later.
LangChain’s broader memory guidance suggests agents can remember:
prior interactions,
user preferences,
and feedback patterns.
How Agent Memory Works
There is no one universal architecture, but most memory systems follow a similar pattern:
Capture useful information from interactions or runs.
Store it in some persistent structure.
Retrieve relevant pieces when a new task begins.
Inject or reference that memory inside the active agent loop.
Update the memory when the task ends or new lessons emerge.
Anthropic’s memory-store docs describe persistent memory as something the agent can carry across sessions. OpenAI’s sandbox-agent docs describe memory as files in the workspace that future runs can learn from. Cloudflare’s system similarly extracts information from conversations and makes it available later.
This pattern means memory is usually part database, part retrieval layer, and part summarization layer. Some systems may use structured files. Some may use embeddings and vector search. Some may organize memory hierarchically. Some may combine fast retrieval with slower deeper reading. A Reddit discussion summarizing Anthropic’s memory approach described a top-down hierarchy of categories and items, but because that is not a primary source, it is safer to treat it only as suggestive commentary rather than authoritative design documentation.
The important point is that modern memory systems are increasingly trying to be structured and queryable, not just archives of old text.
Agent Memory in Current Frameworks
Anthropic
Anthropic’s Managed Agents docs currently have one of the clearest public descriptions of agent memory. They say memory stores let the agent carry information across sessions, and that without them each session starts fresh and loses what it learned when it ends. Anthropic’s AI SDK integration docs also reference a structured memory tool interface for Claude.
Anthropic’s recent “dreaming” work, reported in May 2026, goes a step further by exploring how agents can review prior behavior between sessions and improve future performance. That suggests Anthropic sees memory not just as storage, but as a path toward reflective improvement.
OpenAI
OpenAI’s public Agents SDK docs emphasize that agents keep enough state to complete multi-step work. The SDK memory references distinguish conversational session memory from more persistent sandbox-agent memory. The sandbox memory docs describe future runs learning from prior runs through distilled files in the workspace. OpenAI’s cookbook on memory compaction also suggests that reliable agent design increasingly depends on controlling and compressing memory, not just storing more of it.
LangChain
LangChain’s memory guide describes memory as a system that remembers previous interactions so agents can learn from feedback and adapt to user preferences. It presents memory as a conceptual layer that becomes more important as agents deal with more interactions and more complex tasks.
Cloudflare
Cloudflare’s April 2026 Agent Memory announcement is notable because it frames memory as a managed service. The emphasis is on helping agents remember what matters without overfilling context windows, which reflects the broader industry shift away from raw transcript replay and toward more selective memory systems.
Types of AI Agent Memory (source)
Why Agent Memory Is Hard
Agent memory sounds simple in theory, but it is difficult in practice.
Not everything should be remembered - A good memory system must decide what is worth keeping. If it stores everything, retrieval becomes noisy and expensive. If it stores too little, the agent remains forgetful. Cloudflare’s “remember what matters, forget what doesn’t” phrasing captures this challenge well.
Not every memory should be retrieved every time - Even useful memories are only useful if surfaced at the right moment. Anthropic’s context-engineering post emphasizes that context is finite and must be curated carefully. Too much recalled memory can hurt performance as much as too little.
Memory can become stale or wrong - If a user changes preferences or a project changes direction, old memories may become liabilities. Anthropic’s chat-memory rollouts have emphasized visibility, editing, and disabling memory, which reflects the need for user control over stored memories. Reports on Claude’s consumer memory upgrades also highlighted the ability to view, edit, delete, or disable memory.
Memory design affects safety - A badly designed memory can reinforce bad assumptions, leak sensitive information, or persist things that should have been discarded. Public commentary on consumer AI memory has raised concerns about privacy and unintended psychological effects, though those concerns are broader than agent systems specifically.
Benefits of Agent Memory
Despite the challenges, agent memory can be one of the highest-leverage upgrades to agent quality.
Better continuity - Agents stop feeling stateless and repetitive. Anthropic’s docs make this especially concrete with examples like project conventions and prior mistakes.
Better personalization - Remembered preferences and context let agents adapt to users over time instead of re-learning basics every session. LangChain explicitly mentions adapting to user preferences.
Better efficiency - If the agent already knows relevant context, it can spend fewer tokens re-establishing background and less time asking redundant questions. Cloudflare’s emphasis on avoiding context-window overload speaks directly to this efficiency gain.
Better reliability - OpenAI’s memory-compaction and sandbox-memory patterns suggest that memory can improve reliability by helping agents preserve lessons from prior runs instead of making the same mistakes repeatedly.
Better long-term usefulness - An agent that remembers a project, not just a prompt, becomes much more valuable in ongoing workflows like research, coding, analysis, and operations. This conclusion follows directly from the way Anthropic, LangChain, and OpenAI all frame persistent memory as necessary for multi-session work.
Agent Memory vs Retrieval-Augmented Generation
This is another distinction worth making.
RAG usually means retrieving external documents or knowledge sources relevant to a prompt. Agent memory usually means retrieving information the agent has learned, stored, or distilled from prior interactions or prior runs.
The two can overlap, and in many real systems they do. But they are not identical. An agent may use RAG to access a document library while also using memory to remember user preferences and previous mistakes. OpenAI’s sandbox-memory docs and Anthropic’s memory-store docs both imply this distinction by treating memory as a persistent layer specific to agent continuity rather than just document lookup.
Why Agent Memory Matters for Crypto and Web3
If AI agents are going to become onchain traders, wallet operators, research assistants, governance participants, or A2A commerce actors, they need memory. A trading agent needs to remember strategy settings, prior errors, and risk rules. An AI agent wallet may need to remember user permissions or recurring spending constraints. An autonomous onchain research agent may need project memory to track a thesis over time.
That means agent memory is not just an abstract AI concept. It is a foundational layer for:
AI agent wallets,
autonomous onchain trading,
DeFi systems,
and agent-to-agent commerce.
Conclusion
Agent memory is the layer that lets AI systems accumulate continuity instead of resetting every time.
It includes short-term working context, long-term persistent knowledge, and increasingly even reasoning memory about how the agent should behave in the future. Anthropic, OpenAI, LangChain, and newer infrastructure providers are all now treating memory as a first-class design layer rather than a minor convenience feature.
As AI agents continue to evolve from simple chat interfaces into persistent digital workers, agent memory is becoming one of the most important ideas to understand. For users looking to stay ahead of emerging narratives—from AI agents and autonomous workflows to chain abstraction, RWAs, and PayFi—Phemex offers a secure and user-friendly platform to explore the market, monitor new opportunities, and sharpen your trading edge.